
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 다중검정
- 데이터
- 딥러닝
- 내일배움캠프#til#sqld#eda#데이터리터러시
- 통계학
- Ai
- 머신러닝
- 통계101x데이터분석
- 카이제곱검정
- 통계학공부
- 내일배움캠프#til#sqld
- 책
- A/B테스트
- 내일배움캠프#til#데이터 리터러시
- 통계
- 내일배움캠프#til#파이썬#python#전처리
- vscode
- #내일배움캠프 #사전캠프 #til #sql
- 제1종오류
- 데이터분석
- 이상치 제거
- t검정
- 내일배움캠프#til#sql
- 내일배움캠프#til#파이썬#python#통계학
- 내일배움캠프#til#파이썬#python
- 제2종오류
- 라이브 세션
- 가설검정
- 이상탐지
- 차원축소
Archives
- Today
- Total
Ming's Life
[내일배움캠프] 16일차 본문
1. 오늘 학습 키워드
- 데이터 전처리 및 시각화
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
데이터 전처리
데이터 전처리 : 내가 원하는 데이터를 보기 위해 하는 모든 활동
데이터 전처리 어떻게 해야하나 ..
- 데이터 전달의 목정성
- 데이터 전달의 효과성
데이터 다루기 Excel vs Pandas
- 자동화 프로그래밍 기능
- 대용량 데이터 처리
- 복잡한 데이터 처리 및 분석
- 확장성과 유연성
- 버전 관리
Pandas란 ?
- Python에서 데이터를 조작하고 쉽게 분석할 수 있게 도와주는 라이브러리
Pandas 구조
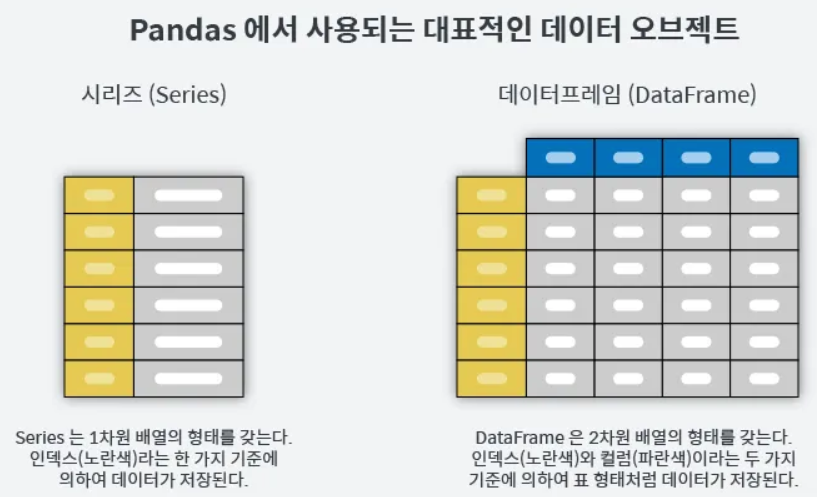
- DataFrame = 표 형태
- index : 각 아이템을 특정할 수 있는 고유의 값 (엑셀에서는 좌측 열순서로 생각하면됨)
- columns : 하나의 속성을 가진 데이터 집합
- Series = 하나의 속성을 가진 데이터 집합 (= DataFrame 표에서 열 1줄이라고 생각하면 쉬움)
- value + index
- import 명령어를 통해서 pandas 라이브러리를 불러오자
import pandas as pd
# pandas 라이브러리를 불러올 것이며 이제부터 pandas를 pd라고 부를게 !
# 에러날 경우 !pip install pandas #실행- 오픈소스 데이터 셋을 불러오자
import seaborn as sns
# seaborn은 데이터를 시각화 하는 라이브러리 중 하나!
# 에러날 경우 !pip install seaborn #실행
data = sns.load_dataset('tips')
# tips라는 이름의 데이터 셋을 불러와서 data 변수에 저장
data
# 데이터 출력
*Tip 파일 경로 찾는 방법
- Window
- 파일 탐색기(File Explorer)를 사용하여 파일 경로 찾기:
- 파일 탐색기를 열고 원하는 파일 또는 폴더를 찾은 후, 주소 표시줄(Address Bar)에 파일 경로가 표시됩니다. 이 경로를 복사하여 사용하거나, 마우스 오른쪽 버튼을 클릭하고 "속성(Properties)"을 선택하면 파일 또는 폴더의 속성 창에서 경로를 확인할 수 있습니다.
- 명령 프롬프트(Command Prompt)를 사용하여 파일 경로 찾기:
- 명령 프롬프트(cmd)를 열고, cd 명령어를 사용하여 원하는 디렉토리로 이동합니다. 그리고 pwd 명령어를 입력하면 현재 디렉토리의 경로를 확인할 수 있습니다.
- Mac
- Finder를 사용하여 파일 경로 찾기:
- Finder를 열고, 원하는 파일 또는 폴더를 찾은 후, 상단의 경로 표시줄(Address Bar)에 파일 경로가 표시됩니다. 이 경로를 복사하여 사용하거나, 파일 또는 폴더를 선택한 후 마우스 오른쪽 버튼을 클릭하여 "정보 보기(Get Info)"를 선택하면 파일 또는 폴더의 경로를 확인할 수 있습니다.
- 터미널(Terminal)을 사용하여 파일 경로 찾기:
- 터미널을 열고, pwd 명령어를 입력하면 현재 작업 디렉토리의 경로를 확인할 수 있습니다.
- 엑셀/CSV 데이터 불러오기
# pd.read_excel('파일경로/파일명.확장자')
# 엑셀 불러오기
pd.read_excel('./파일명.xlsx') # ./ ==> 현재 내가 있는 위치라는 의미
# csv 파일 불러오기
pd.read_csv('./파일명.xlsx')
데이터 저장하기
- pd.to_csv(’파일경로/파일명.확장자’ , index = False)
- pd.to_excel(’파일경로/파일명.확장자’ , index = False)
df = 데이터프레임 # 저장하고 싶은 데이터
df.to_csv('./newfile.csv', index = False)
인덱스(Index)
- 인덱스 : 데이터프레임(DataFrame) 또는 시리즈(Series)의 각 행 또는 각 요소에 대한 식별자입니다.
- DataFrame 자료구조에도 인덱스를 설정할 수 있음
- 0부터 시작하는 숫자 뿐아니라 임의로 문자로 적용할 수 있음
- 아예 처음부터 파일 불러올때 , 인덱스를 지정하는 것도 가능
- 인덱스의 특징
- 고유성(Uniqueness): 각 행은 유일한 인덱스 값을 가져야함. 중복된 인덱스 값을 가질 수 없음.
- 불변성(Immutability): 불변성을 가진다. 즉, 한 번 생성된 인덱스는 변경(수정)할 수 없습니다.
# Pandas에서 사용자가 직접 설정한 인덱스를 변경하는 예시
import pandas as pd
# 사용자가 직접 인덱스를 설정한 데이터프레임 생성
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']}, index=['idx1', 'idx2', 'idx3'])
# 인덱스 변경 (대체)
df.index = ['new_idx1', 'new_idx2', 'new_idx3']
print(df)
3.조작 및 탐색(Manipulation and Retrieval): 인덱스를 사용하여 데이터프레임 또는 시리즈의 특정 행을 선택하거나 탐색할 수 있습니다.
4.정렬(Sorting): 인덱스를 기준으로 데이터프레임 또는 시리즈의 행을 정렬할 수 있습니다.
컬럼(Column)
- 컬럼
- 데이터프레임(DataFrame)의 열(또는 변수)을 나타냅니다.
- 데이터프레임은 행과 열로 구성되며, 각 열은 서로 다른 종류의 데이터를 담고 있습니다.
- 데이터프레임의 세로 방향에 있는 데이터들을 컬럼이라고 부릅니다.
- 컬럼의 특징
- 고유한 이름(라벨)을 가지고 있으며, 해당 컬럼의 데이터를 식별하는 데 사용
- 특정한 종류의 데이터를 담고 있고 숫자, 문자열, 날짜 등 다양한 유형의 데이터를 포함할 수 있음
- 시리즈(Series) 객체로 구성되어 있으며, 시리즈는 동일한 데이터 유형을 가진 1차원 배열과 유사함
- 데이터프레임의 일부로 간주되며, 해당 열의 데이터를 조작하고 접근할 수 있는 인터페이스를 제공함
# 컬럼 예시
import pandas as pd
# 데이터프레임 생성
data = {
'이름': ['Alice', 'Bob', 'Charlie'],
'나이': [25, 30, 35],
'성별': ['여', '남', '남']
}
df = pd.DataFrame(data)
# 각 컬럼 출력
print(df['이름']) # '이름' 컬럼 출력
print(df['나이']) # '나이' 컬럼 출력
print(df['성별']) # '성별' 컬럼 출력
파일이 깨져서 불러와져요!!
- Pandas에서 파일을 불러올 때 파일의 텍스트 데이터를 읽어오는 과정에서 파일의 인코딩 방식을 정확히 지정해야 올바르게 데이터를 읽어올 수 있습니다.
- 인코딩은 한글과 같은 Ascii 범위를 벗어난 문자를 표현하기 위한 변형 작업이라고 이해하시면 쉽습니다. 하지만, 문제는 이러한 인코딩 방식이 여러가지 입니다.
- 모두가 하나의 인코딩을 사용하면 괜찮겠지만, 한글만 하더라도 대표적으로 Microsoft사에서 만든 cp949/ms949 인코딩, euc-kr인코딩, utf-8 인코딩 등등 수많은 인코딩이 존재합니다.
- 즉, 인코딩이 동일하지 않기 때문에 파일이 만약 cp949로 인코딩이 되어 있다고 가정했을 때 이 파일을 utf-8인코딩 방식으로 읽어오려고 한다면, 잘못된 Byte 변환을 하기 때문에 깨짐 현상이 일어납니다.
import pandas as pd
# UTF-8 인코딩으로 파일 불러오기
data = pd.read_csv('file.csv', encoding='utf-8')
# ASCII 인코딩으로 파일 불러오기
data = pd.read_csv('file.csv', encoding='ascii')
iloc[로우,컬럼] : 인덱스 번호로 선택하기
- 행번호(로우)와 열번호(컬럼)를 통해 특정 행과 열 데이터를 선택할 수 있습니다.
data.iloc[0,2]
#행과 열 번호를 통해 특정 데이터를 선택할 수 있음import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# iloc을 사용하여 특정 행과 열 선택
selected_data = df.iloc[1:4, 0:2] # 인덱스 1부터 3까지의 행과 0부터 1까지의 열 선택
print(selected_data)
loc[로우,컬럼] : 이름으로 선택하기
- 인덱스가 번호가 아니고 특정 문자일 경우
data.loc['행이름' , '컬럼명']
# 행이름과 컬럼명을 통해서도 특정 데이터를 선택할 수 있음import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# loc을 사용하여 특정 행과 열 선택
selected_data = df.loc['b':'d', 'A':'B'] # 레이블 'b'부터 'd'까지의 행과 'A'부터 'B'까지의 열 선택
print(selected_data)
3. 학습하며 겪었던 문제점 & 에러
반복 학습 필요
4. 내일 학습 할 것은 무엇인지
SQL / Python 코드카타 , 파이썬 공부
'내일배움캠프' 카테고리의 다른 글
| [내일배움캠프] 18일차 (0) | 2025.06.05 |
|---|---|
| [내일배움캠프] 17일차 (0) | 2025.06.04 |
| [내일배움캠프] 14일차 (0) | 2025.05.29 |
| [내일배움캠프] 13일차 (3) | 2025.05.28 |
| [내일배움캠프] 12일차-1 (0) | 2025.05.27 |