
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 카이제곱검정
- 딥러닝
- Ai
- 가설검정
- 통계학공부
- #내일배움캠프 #사전캠프 #til #sql
- 데이터분석
- 통계학
- 라이브 세션
- 이상탐지
- 머신러닝
- vscode
- 통계101x데이터분석
- 제1종오류
- 제2종오류
- 내일배움캠프#til#sqld
- 차원축소
- 이상치 제거
- 내일배움캠프#til#sqld#eda#데이터리터러시
- A/B테스트
- 내일배움캠프#til#파이썬#python#전처리
- 내일배움캠프#til#파이썬#python#통계학
- t검정
- 다중검정
- 책
- 내일배움캠프#til#데이터 리터러시
- 내일배움캠프#til#sql
- 데이터
- 내일배움캠프#til#파이썬#python
- 통계
- Today
- Total
Ming's Life
통계학_기초 세션 1회차 본문
1. 오늘 학습 키워드
- 통계학 기초 세션
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
통계란 !
데이터는 사실, 통계는 그 사실을 해석하게 해주는 도구
데이터 분석가는 사실을 전달하는 사람이 아닌, 그 사실을 바탕으로 의사결정의 근거를 만들고, 설득하는 사람
통계를 배우는 이유는?
- 데이터를 이해하기 위해 → 이상값, 분포, 편향 등을 확인하고 판단하기
- 다른 사람을 설득하기 위해 → 명확한 수치와 통계적 근거로 이야기하기
- 모델링과 머신러닝의 기반이기 때문 → 선형 회귀, 분류, 확률 등 통계적 개념에 기반한 모델들 이해하기
- 신뢰할 수 있는 추론과 검증을 위해 → 우연인지, 의미 있는 차이인지 구분하기
* 즉, 통계는 데이터를 ‘이해 가능한 정보’로 바꾸는 도구다. 통계를 모르면 데이터는 그냥 숫자에 불과하다.
1. 통계 기초
- 통계학은 본질적으로 '모집단'의 정실을 추정하고 설명하는 것이 목적
모집단과 표본
- 모집단 : 통계학에서 알고자 하는 대상 전체
- 모집단의 모든 데이터를 얻을 수 없기 때문에, 우리는 가진 데이터를 통해 모집단을 ‘추정’하게 된다!
- 모집단을 추정하는 방법
- 전수 조사 : 모집단에 포함된 모든 요소를 조사하는 방법 (분석할 데이터 = 모집단)
- 표본 조사 : 모집단의 일부를 분석하여 모집단 전체의 성질을 추정하는 방법
- 표본 = 모집단의 일부
- 표본 추출 : 모집단에서 표본을 뽑는 것
- 표본 크기 : 표본에 포함된 요소의 개수 (=샘플 수)
빅데이터 시대에는 통계가 필요 없을까?
- 데이터가 많을수록 ‘잘 뽑는 것’, 즉 표본을 잘 추출하는 것이 오히려 더 중요
기술 통계 vs 추론 통계
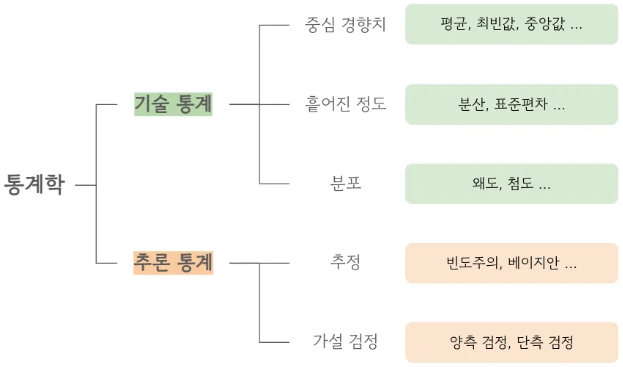
기술 통계 (Descriptive Statistics)
- " 현재의 데이터를 요약하고 설명하는 통계 " - 관촬된 데이터에 집중
- 중심 경향치 : 평균, 중앙값, 최빈값
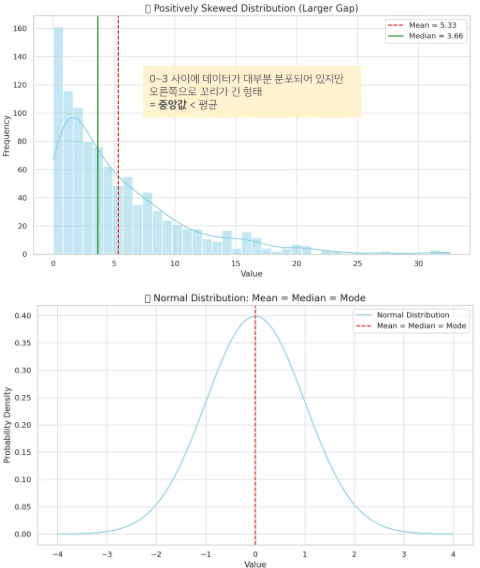
* 왜 평균이 중요할까? - 중심극한정리(Central Limit Theorem)
- 우리가 전체 모집단을 관측할 수는 없지만, 작은 표본들의 평균을 반복해서 구하면,
그 평균들은 정규분포처럼 모이게 된다!
- 흩어진 정도 : 분산, 표준편차 (데이터가 중심에서 얼마나 흩어지고 퍼져 있는지 정도)
| 개념 | 설명 |
|
편차(Deviation)
|
각 데이터가 평균에서 얼마나 떨어져 있는지 |
| 분산(Variance) | 편차를 제곱해서 평균낸 값 |
| 표준편차(Standard Deviation) |
분산에 루트를 씌운 값 (원래 단위로 복원)
|
* 표준편차와 표준오차의 차이
- 표준편차 : 관측값들의 퍼짐 (= 데이터가 평균으로부터 얼마나 퍼져있는가)
- 표준오차 : 표본통계량의 퍼짐 (=여러 표본을 뽑았을 때 표본평균이 얼마나 흔들리는가)
분포
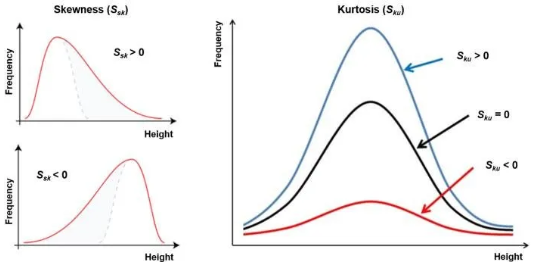
- 왜도 : 데이터 분포의 좌우 비대칭성을 나타내는 척도 (한쪽 방향으로 왜곡된 정도)
- 첨도 : 뾰족함이나 완만함의 정도를 나타내는 척도
추론 통계 (Inferential Statistics)
- 기술 통계는 ‘있는 데이터를 요약’하고, 추론 통계는 ‘없는 모집단을 예측’한다는 차이!!
- 모집단은 전부 관측할 수 없어서 표본을 추출하지만 이 표본이 얼마나 신뢰할 수 있는 정보인지 추정해야 함
- 이 때 필요한 것이 확률
- 추론 통계 = 확률로 불확실성을 다루는 통계이다!
* 통계학 관점에서 데이터 바라보기
- 확률분포 추정 : 데이터가 어떤 확률분포를 따르는지 파악
- 상관관계 및 인과관계 분석 : 두 변수 간의 관계가 단순히 우연인지, 통계적으로 유의미한지 확인
- 예측 모델링 : 하나의 독립 변수로 다른 종속 변수를 예측
⇒ 표본을 통해 모집단의 특성이나 변수 간 관계 등을 예측 및 검정
2. 확률 기초
확률
- 확률 : 발생 여부가 불확실한 사건의 발생 가능성을 숫자로 표현한 것
- 0 ≤ P(A) ≤ 1
- 모든 사건의 확률을 전부 더하면 1
- 확률변수 : 사건의 결과에 따라 값이 확률적으로 정해지는 변수
- 결과가 나오기 전에는 어떤 값이 나올지 모르지만, 그 값들이 나올 확률은 알고 있는 경우
- 이산형 확률변수 : 하나씩 셀 수 있는 변수로 가능한 값이 유한함 (주사위, 나이 등)
- 연속형 확률변수 : 무한히 정밀하게 쪼갤 수 있는 변수로 값이 어떤 구간 내에 연속적으로 존재함 (키, 수면시간 등)
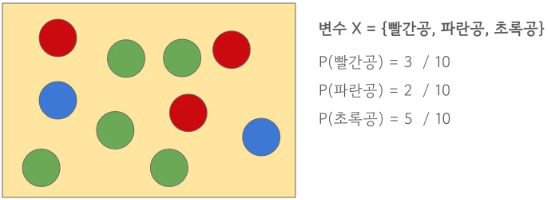
- 실현값 : 실제로 그 확률변수가 가진 구체적인 값 (공을 뽑았을때 결과값 = 빨간색)
확률분포
- 확률분포 : 확률변수가 가질 수 있는 값과 그에 대한 발생 확률 간의 관계를 정리한 것
- x축 : 확률변수, y축 : 그 값이 나올 가능성(확률 또는 밀도)
- 이산형 : 셀 수 있는 값 (유한 개수) - 막대 그래프
- 연속형 : 실수처럼 연속적인 값 (무한) - 부드러운 곡석

- 연속형 확률분포의 특징
- 특정한 한 점의 값의 확률은 0 (소수점 이하 자리가 무사한히 계속될 수 있으므로)
- 구간으로 확률을 계산해야 한다!
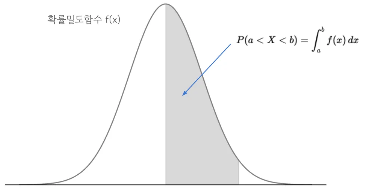
* 확률분포는 왜 추론통계에서 중요할까?
- 현실의 모집단은 관찰이 불가능하기 때문에 수학적으로 확률분포로 가정한다.
- 이 때, 우리가 수집한 데이터(표본)는 이 분포에서 나온 실현값으로 생각한다.
- 즉, 통계적 추론 = 실현값을 바탕으로 어떤 분포에서 나왔는지 추정하는 과정
⇒ 우리는 데이터를 통해 그 데이터를 만들어낸 ‘보이지 않는 분포’를 알아내려 한다!
기대값
- 기댓값(expected value) : 확률변수가 오랜 반복에서 평균적으로 기대되는

- 이산형 확률변수 기댓값
- 한 게임에서 주사위를 던져 나온 수만큼 코인을 얻는다. 이 때 기대값은?

- 연속형 확률변수 기댓값
- 어떤 제품 수명을 0에서 1사이의 균등분포로 모델링한다. 이 때 기댓값은?
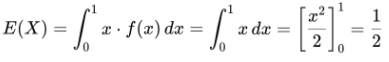
조건부확률
동시확률분포(확률변수가 2개일 때)
- 확률변수가 여러 개라면 그 사이의 관계성을 생각해야 한다!
- 확률변수 2개를 동시에 생각할 때의 확률분포를 동시확률분포 P(X, Y)라 함
- 독립 : 2개의 확률변수에 대한 동시확률분포 P(X, Y) = P(X) * P(Y)
- 한쪽이 어떤 값을 취하든지, 다른 한쪽의 발생 확률은 변하지 않는다!
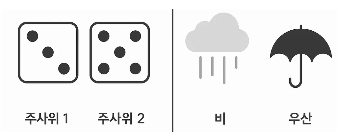
조건부확률 ⭐️⭐️⭐️
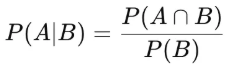
- 어떤 정보가 주어졌을 때, 다른 사건이 일어날 확률
- P(X | Y) : Y라는 정보가 주어졌을 때, X가 일어날 조건부 확률
- Y 에 대한 정보가 생기면, X에 대한 불확실성을 줄일 수 있다.
- ‘비가 온다’는 정보가 주어졌을 때 ‘우산을 쓸’ 확률이 올라간다.
- 즉, Y의 정보로 X의 확률이 달라진다.
* 독립과 의존
- 독립 (Independent) : X, Y가 서로 영향을 주지 않음 → P(X | Y) = P(X)
- 의존 (Dependent): Y의 정보가 X의 확률을 바꿈 → P(X | Y) ≠ P(X)
조건부확률 활용
- 추론 통계는 언제나 어떤 조건 하에 무언가를 추정하거나 검정하는 작업
- 조건부확률은 추론 통계의 핵심적인 수학
| 추론 상황 | 조건부확률적 해석 |
| 가설 검정 | 귀무가설이 참이라는 조건 하에 이 결과가 나올 확률은? |
| 신뢰구간 | 이 표본 평균이 주어졌을 때, 모평균이 들어갈 수 있는 범위는? |
| 모형 예측 | X를 알 떄, Y가 나올 확률은? |
| 베이즈 추론 | 데이터를 관측한 뒤, 어떤 가설이 맞을까? |
🔥 베이즈 정리 (Bayes’ Theorem)
- 베이즈 정리 : 이미 알고 있는 정보(조건)을 바탕으로, 어떤 사건이 일어났을 가능성(사후확률)을 계산
- 조건부확률을 거꾸로 바꿔서 구하는 공식
- 즉 우리는 P(A | B)를 알고 싶은데, 현재 데이터로는 P(B | A) 정보가 있는 상황

3. 추론 통계
추정과 가설검정
추정 (Estimation)
- 모집단의 평균, 비율 등은 알 수 없기에 ‘표본’을 통해 ‘추정’
- 하나의 값만이 아니라 ‘범위’로 말하는 것이 더 정확함 (=신뢰구간)
예) 평균 키는 170cm, 95% 신뢰수준에서 +- 1.5cm
- 이 때 범위를 정하기 위해 표본평균의 분포가 정규분포를 따른다는 전제를 사용
가설검정 (Hypothesis Testing)
- 어떤 주장이 우연인지, 아니면 통계적으로 의미 있는지를 검정하는 과정
예) 남성과 여성의 평균 신용등급 차이가 있는가?
- 표본 통계량이 정규분포 위에서 얼마나 ‘멀리’ 떨어져 있는가(Z값)를 보고 판단
- 이 면적이 p-value → 작을수록 ‘우연히 이렇게 튀었을 확률’이 낮다 = 귀무가설 기각
- 통계검정은 대부분 정규분포나 t분포 위에서 이뤄진다!
정규분포(Normal Distribution)
정규분포 : 중앙에 값이 몰리고 양 끝으로 갈수록 희박해지는 자연스러운 현상 분포
- 정규분포는 평균과 분산을 통해 모양이 정해진다!
- 종 모양의 연속형 확률 분포

정규분포 특징
- 평균 = 최빈값 = 중앙값 (대칭 구조)
- 확률밀도함수의 전체 면적 = 1 (면적 = 확률)
정규분포는 왜 중요할까?
- 현실에서는 전수조사가 어려움 → 모집단이 정규분포라고 가정하면 표본을 통해 모집단 특성 추정 가능
- 예측 가능한 범위:
- 평균 ± 1σ : 약 68.3%
- 평균 ± 2σ : 약 95.4%
- 평균 ± 3σ : 약 99.7%
→ 이 범위를 확률 해석에 활용할 수 있음
- 예시
- ex. 대한민국 20대 키가 정규분포(μ=170, σ=7)라면?
- 무작위로 뽑은 20대 한 명의 키가 163 ~ 177에 들어갈 확률 : 약 68%
- 내가 수집한 데이터 100명에 대해 163~177 비율이 68%에 가까우면 정규분포 가정이 타당함을 뒷받침할 수 있음
- 정규분포 가정은 추론통계의 핵심 기반
- 특히, 가설검정에서 p-value를 해석할 수 있는 전제가 된다.
- 우리가 관측한 데이터가 정규분포에 “가깝다” → 모집단도 정규분포를 따른다고 추정하고 통계 분석 진행
표준화

- 정규분포는 평균과 표준편차에 따라 모양이 달라짐 → 이걸 어떻게 비교할 수 있을까?
- 예를 들어, 시험 점수 90점과 키 182cm는 서로 다른 기준이라 직접 비교하기 어려움
- 이 기준선을 하나로 통일하는 작업이 필요함 → 표준화(Standardization)
- Z : (내 점수 - 평균) / 표준편차 = 내 점수가 평균에서 얼마나 떨어져 있는지에 대한 ‘상대적인 위치’
- Z = 1.0 → 평균보다 1σ만큼 큼 → 상위 약 15.9%
- Z = -2.0 → 평균보다 2σ만큼 작음 → 하위 약 2.3%
표준정규분포
- 평균 0, 표준편차 1인 정규분포
- Z∼N(0,1)
- 모든 정규분포는 Z변환을 통해 표준정규분포로 바꿀 수 있음
- 그럼 이제는 모든 문제를 Z분포 하나만 알면 해결 가능!
- Z테이블 한 장으로 확률을 계산
- 통계 검정(t-test, 회귀분석 등)에서 비교 기준으로 사용
- Z값(표준점수)를 이용해 다양한 정규분포의 누적확률을 하나의 표로 계산 가능

이번 강의 요약
데이터는 늘 한정되어 있지만, 우리는 그걸로 더 큰 세상을 추론해야 한다.
추론 통계는 ‘표본’을 통해 ‘모집단’을 이해하게 해주는 도구이다.
3. 학습하며 겪었던 문제점 & 에러
이해하는데 많은 어려움이 있다 .. 복습을 많이 해야겠다.
4. 내일 학습 할 것은 무엇인지
통계학 공부