
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 라이브 세션
- 내일배움캠프#til#파이썬#python#전처리
- 데이터분석
- 이상치 제거
- 내일배움캠프#til#데이터 리터러시
- 책
- 이상탐지
- 통계101x데이터분석
- 데이터
- 가설검정
- 차원축소
- 다중검정
- 통계
- 내일배움캠프#til#파이썬#python
- 내일배움캠프#til#sqld
- t검정
- 카이제곱검정
- 통계학공부
- #내일배움캠프 #사전캠프 #til #sql
- 내일배움캠프#til#sqld#eda#데이터리터러시
- 딥러닝
- 머신러닝
- A/B테스트
- Ai
- 내일배움캠프#til#sql
- 내일배움캠프#til#파이썬#python#통계학
- 제1종오류
- vscode
- 통계학
- 제2종오류
- Today
- Total
Ming's Life
머신러닝(클러스터링) 본문
1. 오늘 학습 키워드
- 머신러닝 기초
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
1. 비지도 학습 개요
☑️ 비지도 학습이란?
- 비지도 학습(Unsupervised Learning)은 정답(레이블) 없이 데이터에서 패턴이나 구조를 찾는 머신 러닝 기법을 의미
- 활용 영역
- 데이터의 군집화(Clustering)
- 차원 축소(Dimensionality Reduction)
- 이상치 탐지(Anomaly Detection) 등
☑️ 지도 학습과의 비교
- 지도 학습(Supervised Learning)
- 입력 데이터에 대한 정답(레이블)을 알고 있는 상태에서 모델을 학습하여, 새로운 데이터가 들어왔을 때 레이블을 예측.
- ex) 이미지 분류, 스팸 메일 분류
- 비지도 학습(Unsupervised Learning)
- 별도의 레이블이 없고, 오직 입력 데이터만으로부터 구조를 파악.
- ex) 고객 그룹화(세분화), 문서 토픽 분류
핵심 포인트! 비지도 학습에서는 ‘라벨’ 대신 ‘데이터 자체의 유사성과 패턴’에 집중
2. 군집 분석(Clustering)의 개념
☑️ 군집 분석이란 ?
- 비슷한 특성을 가진 데이터들을 묶어서(Cluster) 각 그룹 내 데이터들끼리의 유사도를 최대화하고, 다른 그룹과의 차이는 최대화하는 기법.
목적
1️⃣ 데이터의 구조 파악 : 정답 없이 데이터의 자연스러운 분포를 확인
2️⃣ 세분화(Segmentation) : 마케팅에서는 고객 세분화를, 제조업에서는 센서 데이터로 기계 작동 패턴 분류 등을 수행
☑️ 군집 분석의 절차
1. 데이터 수집 및 전처리
: 이상치 제거, 결측치 처리, 스케일링/정규화
2. 군집 수 또는 파라미터 설정
: K-Means의 경우 k 설정, DBSCAN은 거리(ε), 최소 데이터 수(minPts) 등
3. 군집화 알고리즘 적용
: 설정에 따라 알고리즘 수행
4. 결과 해석 및 평가
: 실루엣 계수 등 군집 평가 지표 활용
5. 사후 활용
: 마케팅 전략, 제품 개선, 이상치 탐지 등
3. 주요 군집 분석 알고리즘 소개
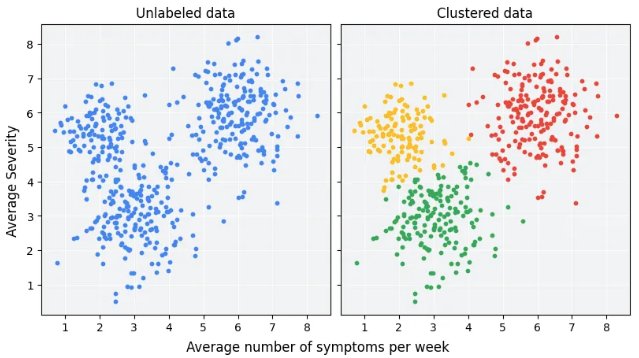
☑️ K-Means
1. 알고리즘 개요
: 미리 군집 수 k를 지정해야 함
: 무작위로 k개의 중심(centroid)을 선택 후, 각 데이터 포인트를 가장 가까운 중심에 할당
: 각 군집의 중심을 다시 계산하고 재할당하는 과정을 반복
: 군집 내 데이터와 중심 간 거리의 제곱합을 최소화
2. 장점
: 계산 속도가 빠르고 구현이 간단
: 대용량 데이터에도 비교적 잘 작동
3. 단점
: 군집 수 k를 미리 알아야 함
: 이상치에 취약(중심값에 영향을 미침)
: 구형(球形) 구조가 아닌 복잡한 형태의 분포를 파악하기 어려움
4. 예시
: 고객 데이터를 나이, 월평균 지출액, 자주 구매하는 카테고리(One-hot 인코딩 후 스케일링 적용) 등을 가지고 분석
: k=3으로 설정한다면 “저가 위주의 고객”, “중간 가격대 선호 고객”, “고가 제품 위주 고객” 등으로 군집이 나뉠 수 있음
☑️ DBSCAN(Density-Based Spatial Clustering of Applications with Noise)

1. 알고리즘 개요
: 밀도 기반 군집화 기법. 일정 거리(ε) 내 데이터가 많으면(최소 포인트 수 minPts 이상) 그 영역을 ‘밀도가 높다’고 판단해 하나의 군집으로 결정
: k를 미리 설정하지 않아도 되며, 노이즈 포인트(어느 군집에도 속하지 않는 점)을 구분할 수 있음
2. 장점
: 군집 수를 사전에 알 필요가 없음
: 노이즈와 이상치를 자연스럽게 처리
: 구형이 아닌 복잡한 형태의 군집도 잘 찾아냄
3. 단점
: 파라미터 ε와 minPts에 민감
: 데이터 밀도가 균일하지 않으면 성능이 떨어질 수 있음
4. 예시
: 지리정보(GIS) 분석에서 지역별로 가게가 얼마나 밀집되어 있는지 분석할 때 사용
: 특정 지점에 가게가 몰려 있으면 하나의 군집, 중간에 뜨문뜨문 있는 가게는 노이즈(Cluster에 속하지 않는 포인트)로 분류
☑️ 계층적 클러스터링(Hierarchical Clustering)

1. 알고리즘 개요
: 데이터 포인트 각각이 하나의 군집으로 시작 → 유사도가 가장 높은 군집들끼리 병합 → 최종적으로 하나의 군집(트리) 형성
: 또는 하나의 군집에서 시작해 분할해 나가는 방법도 있음(분할적 접근)
: 덴드로그램(Dendrogram)으로 시각화가 가능
2. 장점
: 군집의 계층적 구조 파악이 쉬움(덴드로그램)
: 군집 수를 명확히 결정하지 않아도, 덴드로그램의 특정 높이(cut)에 따라 유연하게 군집 개수 결정 가능
3. 단점
: 계산 복잡도가 높아서 대규모 데이터에 적용하기 어려움
4. 예시
: 유전자 데이터 분석: 유전자 발현 패턴이 유사한 것끼리 계층적으로 묶어, 생물학적 특성을 추론
: 다양한 문서(텍스트) 클러스터링에서 단어의 사용 빈도 등을 기반으로 문서 구조를 시각화
☑️ 클러스터링 코드 예시
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
# 1. 데이터 로드
iris = load_iris()
X = iris.data
y = iris.target # 실제 품종 레이블(군집 학습 자체에는 사용하지 않음)
# 3. K-Means
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# 4. DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# 5. 계층적 클러스터링 (AgglomerativeClustering)
agg = AgglomerativeClustering(n_clusters=3)
agg_labels = agg.fit_predict(X)
# 6. 각 군집 결과의 실루엣 지수 평가
kmeans_sil = silhouette_score(X, kmeans_labels)
dbscan_sil = silhouette_score(X, dbscan_labels)
agg_sil = silhouette_score(X, agg_labels)
print("=== 군집 결과 비교 ===")
print("K-Means: 실루엣 점수 =", kmeans_sil, "| 클러스터 라벨 =", np.unique(kmeans_labels))
print("DBSCAN: 실루엣 점수 =", dbscan_sil, "| 클러스터 라벨 =", np.unique(dbscan_labels))
print("Agglomerative: 실루엣 점수 =", agg_sil, "| 클러스터 라벨 =", np.unique(agg_labels))
# 7. 시각화를 위해 PCA로 차원 축소 (2차원)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 8. 군집 결과 시각화
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# K-Means 시각화
axes[0].scatter(X_pca[:, 0], X_pca[:, 1], c=kmeans_labels)
axes[0].set_title("K-Means")
# DBSCAN 시각화
axes[1].scatter(X_pca[:, 0], X_pca[:, 1], c=dbscan_labels)
axes[1].set_title("DBSCAN")
# Agglomerative 시각화
axes[2].scatter(X_pca[:, 0], X_pca[:, 1], c=agg_labels)
axes[2].set_title("Agglomerative")
plt.tight_layout()
plt.show()
☑️ 코드 해설
- 데이터 로드를 진행
- load_iris 함수를 사용하여 Iris 데이터를 가져온다.
- 4차원의 연속형 특성(꽃받침 길이·폭, 꽃잎 길이·폭)과 3개 품종 레이블이 존재한다.
- 학습/테스트 데이터 분할은 선택 사항이지만, 예시로 70% 데이터를 학습에, 30%를 테스트에 사용하도록 분할했다.
- 세 가지 군집 기법으로 학습을 수행한다.
- K-Means: n_clusters=3으로 클러스터를 3개로 분할한다.
- DBSCAN: eps=0.5, min_samples=5를 기본 설정으로 사용한다.
- AgglomerativeClustering: n_clusters=3으로 계층적 군집을 수행한다.
- 군집 결과 평가로 실루엣 지수(Silhouette Score)와 Davies-Bouldin Index를 각각 계산해 본다.
- silhouette_score(X_train, labels)는 실루엣 지수를 계산하며, 값이 클수록(최대 1) 군집화가 잘 되었다고 볼 수 있다.
- davies_bouldin_score(X_train, labels)는 Davies-Bouldin 지수로, 값이 낮을수록 군집화 품질이 우수함을 의미한다.
- PCA로 2차원 축소 후 군집 결과를 시각화한다.
- 4차원 데이터를 2차원으로 변환하여 산점도를 그리므로, 실제 군집 분포가 단순화되어 보일 수 있다.
- 그래프에서는 각각의 모델(K-Means, DBSCAN, Agglomerative) 결과를 다른 축에 표시하여 비교한다.
4. 군집 분석 평가 방법
☑️ 실루엣 계수(Silhouette Score)
- 각 데이터 포인트의 응집도(a)와 분리도(b)를 이용해 계산
- 응집도(a) : 같은 군집 내 데이터와의 평균 거리
- 분리도(b) : 가장 가까운 다른 군집과의 평균 거리
- 계산 공식

- 범위
- -1 ~ 1
- 1에 가까울수록 해당 데이터가 잘 군집되었음을 의미
- 0 근처면 군집 경계에 위치
- 0보다 작으면 잘못된 군집화 가능성
☑️ Davies-Bouldin Index
- 군집 내 분산과 군집 간 거리의 비율을 활용
- 각 군집에 대해 다른 군집과의 거리를 비교하면서, 군집끼리 얼마나 겹치는지 측정
- 범위
- 0 이상
- 값이 0에 가까울수록 군집 간 구분이 잘 되어 있음
- 값이 커질수록 군집 간 겹침이 많아 군집화 품질이 낮음
☑️ 내부 평가 vs. 외부 평가
- 내부 평가(Internal Evaluation)
- 데이터 내부의 정보(분산, 거리 등)를 활용해 평가 (실루엣 계수, Davies-Bouldin Index 등)
- 외부 평가(External Evaluation)
- 이미 알려진 레이블(정답)과 군집 결과를 비교(정답이 있을 때만 가능)
총 정리
1. 비지도 학습은 레이블 없이 데이터 구조를 파악하는 데 사용
2. 군집 분석은 유사한 데이터끼리 묶어 세분화하고, 다양한 분야에서 활용
3. K-Means, DBSCAN, 계층적 군집 알고리즘별 특성을 파악해 상황에 맞춰 선택
4. 군집화 결과는 실루엣 계수, Davies-Bouldin Index 등으로 정성·정량적으로 평가
5. 다양한 실무 분야에서 고객 세분화, 이상치 탐지 등으로 적극 활용 가능
💡앞으로 알면 더 좋은 내용!
: 이상치 탐지(Anomaly Detection)나 토픽 모델링(Topic Modeling) 영역과도 연계해 폭넓은 분석 수행
: 실무에서는 여러 알고리즘을 시도해보며 최적의 군집 수 및 파라미터를 찾는 과정(Iteration)이 필수
* 토픽 모델링이란?
: 문서를 이루는 단어들의 패턴(분포)을 분석하여,
여러 문서에 걸쳐 자주 함께 등장하는 단어들의 집합을 하나의 토픽(주제)으로 간주하는 방식
❗결론
: 군집 분석은 단순히 “데이터를 몇 개 그룹으로 묶었다”에서 끝나지 않고,
왜 그룹이 그렇게 나뉘었는지(의미 해석)와 어떻게 업무에 활용할지(실행 전략)까지 연결해야 비즈니스 가치를 창출
'머신러닝' 카테고리의 다른 글
| 머신러닝(이상탐지) (1) | 2025.07.08 |
|---|---|
| 머신러닝(차원축소) (3) | 2025.07.08 |
| 머신러닝(앙상블 기법) (0) | 2025.07.07 |
| 머신러닝(분류) (1) | 2025.07.04 |
| 머신러닝(회귀) (2) | 2025.07.03 |



