
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 제2종오류
- 제1종오류
- 데이터
- #내일배움캠프 #사전캠프 #til #sql
- 내일배움캠프#til#파이썬#python
- 내일배움캠프#til#sqld
- vscode
- 라이브 세션
- 내일배움캠프#til#파이썬#python#전처리
- 내일배움캠프#til#sqld#eda#데이터리터러시
- 통계
- 차원축소
- A/B테스트
- 통계학
- 딥러닝
- 통계101x데이터분석
- 다중검정
- 이상치 제거
- 내일배움캠프#til#데이터 리터러시
- 머신러닝
- 내일배움캠프#til#파이썬#python#통계학
- 가설검정
- 내일배움캠프#til#sql
- 이상탐지
- Ai
- 카이제곱검정
- 통계학공부
- 책
- t검정
- 데이터분석
Archives
- Today
- Total
Ming's Life
머신러닝(차원축소) 본문
1. 오늘 학습 키워드
- 머신러닝 기초
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
1. 차원 축소가 왜 필요할까?
☑️ 차원 축소의 필요성
- 고차원 데이터란?
- 데이터의 피처(변수)가 매우 많은 상태를 말합니다. 예컨대 이미지 데이터의 경우, 한 장의 이미지를 구성하는 픽셀 수만큼의 피처가 있을 수 있습니다.
- 어떤 문제가 생길까?
- 모델 학습 시 연산 복잡도가 급증하여 시간이 오래 걸림
- 많은 피처들 중 일부는 실제로 중요한 정보를 주지 못하는 노이즈(잡음)일 수 있음
- 차원이 너무 높아지면 데이터를 시각화하기가 어려워 패턴 파악이 힘듬
- 차원 축소의 장점
- 노이즈 제거로 모델 성능 및 일반화 능력을 개선할 수 있음
- 2차원이나 3차원으로 축소하면 시각적으로 직관적인 분석을 할 수 있음
- 데이터의 핵심 구조나 패턴을 더 쉽게 발견할 수 있음
2. 차원 축소 기본 개념
☑️ 선형 차원 축소 vs. 비선형 차원 축소
- 선형 차원 축소
- 데이터를 특정 선형 변환(ex : 행렬 곱)으로 투영하여 차원을 줄이는 기법. PCA가 대표적
- 예를 들면…
- 3차원 공간에 놓인 물체가 있다고 가정
- 빛(광원)을 한 방향에서 비추면, 물체의 그림자가 2차원 벽면(또는 바닥)에 투영됨
- 3차원을 → 2차원 처럼 볼 수 있음
- 즉, 선형 변환이라는 간단 계산만으로 차원축소를 하게 되는 경우!
- 예를 들면…
- 데이터를 특정 선형 변환(ex : 행렬 곱)으로 투영하여 차원을 줄이는 기법. PCA가 대표적
- 비선형 차원 축소
- 데이터가 복잡한 기하학적 구조를 가질 때, 선형 변환만으로는 충분치 않을 수 있으므로 비선형 맵핑을 이용. t-SNE, UMAP 등이 이에 해당
- 예를 들면…
- 종이 한 장이 있고, 그 종이에 그림(데이터)이 복잡하게 그려져 있다고 가정
- 이 종이는 실제로는 2차원이지만, 종이가 구겨져서(휘어지고 말려서) 3차원 공간 속에서 복잡한 형태를 띠고 있음
- 우리가 종이를 펼쳐서 다시 평평한 2차원 상태로 만들면, 그 원래의 그림을 쉽게 2D에서 볼 수 있음.
- 즉, 구겨져 있는 형태(복잡한 형태)를 펴서 차원 축소를 하게 되는 경우!
- 예를 들면…
- 데이터가 복잡한 기하학적 구조를 가질 때, 선형 변환만으로는 충분치 않을 수 있으므로 비선형 맵핑을 이용. t-SNE, UMAP 등이 이에 해당
☑️ 차원 축소와 노이즈 제거
- 대부분의 데이터에는 잡음(irrelevant feature)이 포함
- 차원 축소 시, 중요한 변동을 잘 설명하지 못하는 데이터는 줄여버림으로써 불필요한 정보를 걸러낼 수 있음
3. PCA (주성분 분석)

☑️ PCA 개념
- 핵심 아이디어
- 데이터에서 가장 ‘분산이 큰 방향(주성분)’을 찾아 그 방향으로 데이터를 투영하면, 그 축이 데이터의 중요한 변동(variance)을 많이 설명할 수 있다.
- 사진 찍을 때 각도를 찾는 예시를 들어서 생각하면…
- 친구가 찍고 싶은 건물(피사의 사탑)이 있는데 건물이 반듯하게 서 있는 모습을 찍고 싶음, 그러나 이 건물은 기울어져 있는 상황
- 이 건물을 카메라로 찍는다고 가정
- 건물이 기울어져 있어서, 찍을 때 어떤 각도로 카메라를 기울이면 가장 잘(넓게) 찍을 수 있을지가 고민하고 적정한 각도로 찍으면 건물이 반듯하게 서 있는 모습을 볼 수 있음
- 위 예시를 데이터로 치면…
- 건물의 각도: 데이터가 놓여 있는 실제 축(변수들)
- 카메라 각도: 우리가 새로 찾고 싶은 “주성분(Principal Component)” 축
- 우리가 가장 이쁘게 보이는 각도를 찾고 싶은 것처럼, PCA는 데이터가 가장 잘 퍼져 있는 방향(가장 큰 분산의 방향)을 찾음
- 사진 찍을 때 각도를 찾는 예시를 들어서 생각하면…
- 데이터에서 가장 ‘분산이 큰 방향(주성분)’을 찾아 그 방향으로 데이터를 투영하면, 그 축이 데이터의 중요한 변동(variance)을 많이 설명할 수 있다.
- 주성분(Principal Component)
- 가장 큰 분산을 갖는 방향을 1주성분으로, 그다음으로 큰 분산을 갖는 서로 직교(90도)하는 방향을 2주성분으로 하는 식으로 이어진다.
- 설명 분산(Explained Variance) 비율
- 몇 개의 주성분만으로 전체 분산의 몇 퍼센트를 설명할 수 있는지 나타낸다.
☑️ 장단점
- 장점
- 계산이 비교적 간단(선형 연산), 결과 해석이 용이(주성분 방향 해석 가능), 노이즈 제거 효과.
- 단점
- 데이터가 선형이 아닌 패턴일 경우 정보 손실이 발생할 수 있음, 매우 복잡한 구조를 충분히 반영하기 어려움.
4. t-SNE와 UMAP
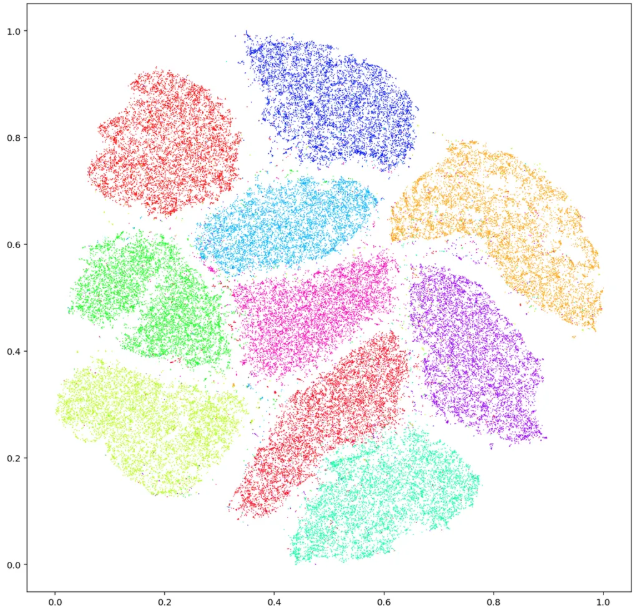
☑️ t-SNE (t-Distributed Stochastic Neighbor Embedding)
- 고차원 공간에서 ‘서로 가까운 데이터 포인트는 가까이, 먼 데이터 포인트는 멀리’ 배치하려고 하는 비선형 차원 축소 기법.
- 동작 원리
- 고차원에서 데이터 간 ‘지역적 확률 분포’를 추정한다(주변 데이터와의 거리를 기반).
- 2차원 혹은 3차원에서 비슷한 확률 분포가 되도록 데이터들을 배치한다.
- 예를 들면…
- 고차원(큰 운동장 같은 공간)에서 자유롭게 사람들이 흩어져 서 있었는데, 이제 작은 교실(2D 공간) 안에 앉혀야 하는 상황
- 친구들 중에는 서로 가깝게 붙어 있기를 원하는 그룹(이웃 관계)이 있음
- 즉, t-SNE는 고차원에서 A가 B와 가까울 확률을 구하고, 2D에서는 그 확률을 최대한 비슷하게 만들도록 위치를 조정
- 장점
- 데이터의 군집이 자연스럽게 시각화되어, 군집별 패턴을 인지하기 쉽다.
- 단점
- 계산 비용이 큰 편(대규모 데이터에는 시간이 오래 걸림).
- 하이퍼파라미터(learning rate, perplexity) 선택에 따라 결과가 달라질 수 있음.
- 시각화 결과 해석이 직관적이지만, 실제 거리 척도가 왜곡될 수 있으니 주의.

☑️ UMAP (Uniform Manifold Approximation and Projection)
- t-SNE와 유사하게 고차원 데이터의 구조를 2D/3D로 매핑하는 비선형 차원 축소 기법. ‘근접 그래프(nearest neighbor graph)’와 ‘Riemannian manifold’ 이론에 기반한다.
- 이를 쉽게 말하면… 위에서 얘기했던 구겨진 종이의 예시!
- 종이가 구겨진 상태는 매니폴드(Manifold)라고 부르는, 비선형적으로 휘어진 공간을 의미
- UMAP은 이 종이가 구겨져 있는 구조에서 가까운 점들은 여전히 가깝게, 먼 점들은 멀리 놓이도록, 매니폴드를 펼쳐 2D로 맵핑
- 이를 쉽게 말하면… 위에서 얘기했던 구겨진 종이의 예시!
- 장점
- t-SNE보다 빠르고, 대규모 데이터에도 비교적 효율적이다.
- 지역적/글로벌 구조를 함께 잘 반영한다.
- 매개변수(예: n_neighbors, min_dist)를 통해 클러스터의 응집도나 분산 정도를 조절할 수 있다.
- 단점
- 알고리즘의 개념이 비교적 복잡하고, 하이퍼파라미터 튜닝을 요한다.
- t-SNE만큼은 아니지만, 여전히 축소 과정에서 정보 왜곡이 발생할 수 있다.
☑️ 차원축소 코드 예시
import numpy as np
import matplotlib.pyplot as plt
# 1. 데이터 로드 (Iris 예시)
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data # (150, 4) 형태: 꽃받침, 꽃잎 길이·너비
y = iris.target # (150,) : 품종 라벨(0, 1, 2)
# 2. PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 3. t-SNE
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne = tsne.fit_transform(X)
# 4. UMAP
# (umap-learn 설치 필요할 수 있습니다 : pip install umap-learn)
from umap import UMAP
umap = UMAP(n_components=2, n_neighbors=15, random_state=42)
X_umap = umap.fit_transform(X)
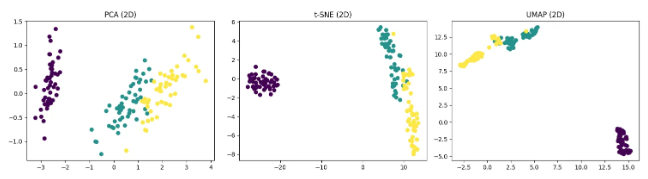
# 5. 시각화 (PCA, t-SNE, UMAP 결과 비교)
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
axes[0].scatter(X_pca[:, 0], X_pca[:, 1], c=y)
axes[0].set_title("PCA (2D)")
axes[1].scatter(X_tsne[:, 0], X_tsne[:, 1], c=y)
axes[1].set_title("t-SNE (2D)")
axes[2].scatter(X_umap[:, 0], X_umap[:, 1], c=y)
axes[2].set_title("UMAP (2D)")
plt.tight_layout()
plt.show()
☑️ 코드 해설
- Iris 데이터셋 로드
- load_iris()를 통해 꽃받침/꽃잎 길이·너비 특성이 들어있는 4차원 데이터를 불러옵니다.
- y는 품종 레이블(0, 1, 2)입니다.
- PCA
- PCA(n_components=2)로 2차원 주성분으로 투영합니다.
- 선형 차원 축소 기법으로 데이터의 분산이 가장 큰 방향으로 축을 잡습니다.
- t-SNE
- TSNE(n_components=2)로 고차원 데이터의 지역적 이웃 구조를 보존하며 2차원으로 매핑합니다.
- 군집(클러스터)이 시각적으로 뚜렷이 분리되도록 나타나는 경우가 많습니다.
- UMAP
- UMAP(n_components=2, n_neighbors=15)로 비선형 매니폴드를 “펴는” 방식의 차원 축소를 수행합니다.
- t-SNE와 비슷하게 군집이 시각적으로 잘 드러나며, 데이터가 큰 경우에도 속도가 빠른 편입니다.
- 시각화
- 3개의 서브플롯을 만들어 각각 PCA, t-SNE, UMAP 결과를 산점도로 그립니다.
- c=y로 각 품종 클래스(0, 1, 2)를 색으로 구분합니다.
- 결과적으로 차원 축소 기법별로 어떤 식으로 데이터 분포가 보이는지 비교할 수 있습니다.
5. 실무 적용 시 고려 사항
1. 데이터 전처리
: 스케일링(표준화, 정규화), 이상치 제거 등을 먼저 수행해야 합니다.
2. 하이퍼파라미터 튜닝
- PCA
- 주성분 개수를 얼마나 선택할지(설명 분산 비율을 확인).
- t-SNE
- perplexity, learning rate, iteration 수.
- UMAP
- n_neighbors, min_dist 등. </aside>
3. 결과 해석
: PCA는 주성분 방향이 어떤 피처 조합과 관련이 있는지 해석 가능.
: t-SNE/UMAP 결과는 시각화를 통해 군집 형태나 분포를 확인하되, 지나친 해석은 지양(거리 자체의 절대적 의미는 왜곡될 수 있음).
4. 성능 측정 및 검증
: 최종 목적(군집 분석, 노이즈 제거, 시각화 등)에 따라 적절한 지표를 사용해 성능을 평가할 수 있음. (차원 축소만의 별도 지표는 없음)
총 정리
1. 고차원 데이터 → 시각화와 연산 복잡도 측면에서 어려움 → 차원 축소가 필요한 이유.
2. PCA: 선형 차원 축소로 계산이 빠르고 해석이 직관적.
3. t-SNE, UMAP: 비선형 구조를 잘 반영하여 2D/3D 시각화에 매우 효과적.
'머신러닝' 카테고리의 다른 글
| 머신러닝(이상탐지) (1) | 2025.07.08 |
|---|---|
| 머신러닝(클러스터링) (2) | 2025.07.08 |
| 머신러닝(앙상블 기법) (0) | 2025.07.07 |
| 머신러닝(분류) (1) | 2025.07.04 |
| 머신러닝(회귀) (2) | 2025.07.03 |
'머신러닝' Related Articles
more



