
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 이상탐지
- 내일배움캠프#til#파이썬#python
- 내일배움캠프#til#sql
- 다중검정
- 책
- 데이터
- 카이제곱검정
- 내일배움캠프#til#파이썬#python#통계학
- 데이터분석
- 차원축소
- 이상치 제거
- Ai
- 가설검정
- 통계
- 내일배움캠프#til#sqld#eda#데이터리터러시
- #내일배움캠프 #사전캠프 #til #sql
- A/B테스트
- 통계학공부
- 제1종오류
- 머신러닝
- t검정
- 통계학
- 내일배움캠프#til#sqld
- 통계101x데이터분석
- 내일배움캠프#til#데이터 리터러시
- 라이브 세션
- 제2종오류
- 딥러닝
- vscode
- 내일배움캠프#til#파이썬#python#전처리
- Today
- Total
Ming's Life
머신러닝(회귀) 본문
1. 오늘 학습 키워드
- 머신러닝 기초
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
1. 회귀 분석 개요
☑️ 회귀 분석이란?
- 종속변수(Y)와 하나 이상의 독립변수(X) 간의 관계를 추정하여, 연속형 종속변수를 예측하는 통계/머신러닝 기법
- ex) “공부한 시간(X)에 따라 시험 점수(Y)가 어떻게 변하는가?” 를 예측
- 지도학습에서의 분류(Classification)와 회귀(Regression)의 차이
- 분류: 결과값이 이산형(클래스 라벨)
- 회귀: 결과값이 연속형(숫자 값)
- 사람의 지능적인 작업을 기계가 수행하도록 만드는 광범위한 개념
☑️ 회귀 모델을 사용하는 이유
1. 미래 값 예측
: 판매량, 주가, 온도 등 실수값 예측에 사용
2. 인과 관계 해석(통계 관점)
: 특정 독립변수가 종속변수에 미치는 영향력을 해석하기 위해
3. 데이터 기반 의사결정
: 추세(Trend) 파악, 자원 배분 등
☑️ 회귀 모델의 대표적 활용 사례
1. 경제
: 주식 가격 예측, 판매량 예측
2. 건강
: 혈압, 콜레스테롤 수치 예측
3. 제조업
: 불량률, 생산량 예측(ex : 온도, 습도, 기계 속도 등의 데이터 이용)
: 생산 설비에 부착된 센서(온도, 진동, 소음 등)에서 수집된 데이터를 바탕으로, 장비 고장 시점을 사전에 예측
2. 선형 회귀 (Linear Regression)
☑️ 개념
- 가정
- 독립변수(X)와 종속변수(Y)가 선형적(일차 방정식 형태)으로 관계를 맺고 있다고 가정
- 회귀식

- β0: 절편(intercept)
- βi: 각 독립변수의 회귀계수(coefficient)

☑️ 선형 회귀 모델 학습 과정
1. 가중치(회귀계수) 초기화
2. 손실함수(Loss Function) 설정
: 주로 MSE(Mean Squared Error) 사용
3. 최적화
: 수학적인 방법(최소자승법), 경사하강법(Gradient Descent) 등을 통해 가중치를 업데이트
4. 학습 완료 후
: β0,β1,…를 얻어서 새로운 입력 값에 대한 예측 수행
- 장점: 해석이 간단, 구현이 쉬움
- 단점: 데이터가 선형성이 아닐 경우 예측력이 떨어짐
☑️ 선형회귀 코드
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 1. 데이터 로드
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
print(X.shape)
print(y.shape)# 2. 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)# 3. 선형회귀 (LinearRegression) 모델
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)# 예측
y_pred_lin = lin_reg.predict(X_test)
# 성능 측정
mse_lin = mean_squared_error(y_test, y_pred_lin)
r2_lin = r2_score(y_test, y_pred_lin)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[LinearRegression 결과]")
print("가중치(coefficient):", lin_reg.coef_)
print("절편(intercept):", lin_reg.intercept_)
print("MSE:", mse_lin)
print("R2 점수:", r2_lin)
print("평균 비율 오차 : ", MPE(y_test, y_pred_lin))
# 4. SGDRegressor 모델
sgd_reg = SGDRegressor(max_iter=6000, tol=1e-3, random_state=42)
sgd_reg.fit(X_train, y_train)# 예측
y_pred_sgd = sgd_reg.predict(X_test)
# 성능 측정
mse_sgd = mean_squared_error(y_test, y_pred_sgd)
r2_sgd = r2_score(y_test, y_pred_sgd)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[SGDRegressor 결과]")
print("가중치(coefficient):", sgd_reg.coef_)
print("절편(intercept):", sgd_reg.intercept_)
print("MSE:", mse_sgd)
print("R2 점수:", r2_sgd)
print("평균 비율 오차 : ", MPE(y_test, y_pred_sgd))
☑️ 코드 해설
- 데이터 로드
- load_diabetes() 함수를 통해 당뇨병 예측용 데이터셋을 로드
- X에는 특성(독립변수)들이, y에는 타겟(종속변수)이 저장
- 학습/테스트 데이터 분리
- train_test_split을 사용하여 80%는 학습용, 20%는 테스트용으로 나눈다.
- random_state=42로 고정하면 재현 가능성을 높일 수 있다.
- LinearRegression 모델 학습 및 예측
- fit() 메서드를 사용해 학습한 후, predict()로 테스트 세트에 대한 예측을 수행
- mean_squared_error, r2_score로 예측 성능을 평가
- SGDRegressor 모델 학습 및 예측
- 확률적 경사하강법 기반의 SGDRegressor 모델을 사용
- max_iter=1000, tol=1e-3 등의 파라미터는 데이터와 상황에 따라 조정 가능
- 마찬가지로 예측 후, MSE와 R2 점수를 통해 모델 성능을 확인
3. 다항 회귀 (Polynomial Regression)
☑️ 개념
- 비선형적인 관계를 다항식(polynomial) 형태로 모델링
- ex) 2차 다항식

- 선형 회귀와 다른 점은, 단순 선형항(X)뿐만 아니라 X^2, X^3,... 같은 고차항을 추가해 비선형 패턴을 학습할 수 있다는 것
☑️ 다항 회귀 적용 예시
- 제조 공정에서의 온도와 반응률 관계가 곡선 형태인 경우
- 건강 데이터에서 나이와 특정 지표(근육량 등)가 단순 선형보다 곡선 형태로 나타나는 경우
☑️ 주의점
- 고차항을 무작정 늘리면 훈련 데이터에는 과도하게 맞춰져 과적합(overfitting) 문제가 발생할 수 있음
- 참고!) 여기서 과적합은 ‘일반화가 잘 되지 않은 상황’이라고 언급하고 추후 ‘앙상블’내용에서 과적합을 자세히 설명
- 모델 복잡도와 일반화 성능 간의 균형을 맞춰야 함
☑️ 다항회귀 코드
import numpy as np
import pandas as pd
from sklearn.datasets import make_friedman1
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.pipeline import Pipeline
# 1) 비선형 데이터 생성 (make_friedman1)
# n_samples: 샘플 개수, n_features: 특성 개수, noise: 잡음 크기
X, y = make_friedman1(n_samples=1000, n_features=5, noise=1.0, random_state=42)
print(X.shape)
print(y.shape)# 2) 학습/테스트 분리
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)# 3) 단순 선형회귀 모델 (비교용)
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_pred_lin = lin_reg.predict(X_test)
mse_lin = mean_squared_error(y_test, y_pred_lin)
r2_lin = r2_score(y_test, y_pred_lin)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[단순 선형회귀 결과]")
print("MSE:", mse_lin)
print("R2:", r2_lin)
print("평균 비율 오차 : ", MPE(y_test, y_pred_lin))
print()
# 4) Polynomial Regression (2차 예시)
poly_model = Pipeline([
("poly", PolynomialFeatures(degree=2, include_bias=False)),
("lin_reg", LinearRegression())
])
poly_model.fit(X_train, y_train)
y_pred_poly = poly_model.predict(X_test)
mse_poly = mean_squared_error(y_test, y_pred_poly)
r2_poly = r2_score(y_test, y_pred_poly)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[다항회귀(2차) 결과]")
print("MSE:", mse_poly)
print("R2:", r2_poly)
print("평균 비율 오차 : ", MPE(y_test, y_pred_poly))
☑️ 코드 해설
- 데이터 생성 (make_friedman1)
- n_samples=1000으로 1000개의 샘플을, n_features=5로 5개의 특성을 생성
- noise=1.0으로 타겟 값에 약간의 랜덤 잡음을 추가
- 학습/테스트 데이터 분리
- train_test_split을 통해 70% 데이터로 학습, 30% 데이터로 테스트
- random_state=42로 설정하여 매번 코드를 실행해도 같은 결과가 재현되도록 했다.
- 단순 선형회귀 모델 학습 및 예측
- 비선형성을 고려하지 않고 LinearRegression만 적용했을 때의 성능을 MSE, R^2, MPE로 측정
- 다항회귀 (Polynomial Regression)
- PolynomialFeatures(degree=2)로 2차 항까지 고려하도록 변환 후, 다시 선형회귀를 적용하는 파이프라인을 구성
- 비선형 패턴을 어느 정도 학습할 수 있으므로, 단순 선형회귀보다 더 좋은 성능이 기대(물론 과적합 위험도 존재).
- 결과 비교
- MSE, R^2 등을 비교하여 단순 선형회귀 대비 다항회귀가 Friedman1 데이터셋에서 어떤 차이를 보이는지 확인할 수 있다.
- 만약 더 높은 차수(예: 3차, 4차)를 적용하거나, 다른 비선형 모델(예: 랜덤 포레스트, SVM 회귀 등)을 사용하면 성능이 달라질 수 있다.
4. 회귀 모델 평가 방법
☑️ MSE (Mean Squared Error)

- 예측값과 실제값의 차이를 제곱하여 평균
- 오차가 클수록 제곱에 의해 더 큰 벌점이 매겨지므로, 큰 오차에 특히 민감
- 평균 제곱 오차라고도 하며, 회귀 모델 평가에서 매우 자주 사용됨
☑️ MAE (Mean Absolute Error)

- 예측값과 실제값의 차이를 절댓값으로 측정한 후 평균
- 예측이 평균적으로 실제값에서 얼마나 벗어났는지 직관적으로 표현
☑️ RMSE (Root Mean Squared Error)

- MAE와 달리 제곱을 통해 큰 오차에 가중치를 더 주는 특징
- 오차가 클수록 패널티가 커지므로, 큰 오차가 중요한 문제에서 자주 사용
☑️ R² (결정 계수)

- yˉ: 종속변수의 평균
- 값의 범위
- 0 ~ 1 (음수가 될 수도 있음)
- 해석
- 1에 가까울수록 학습된 모델이 데이터를 잘 설명한다고 볼 수 있음
- 0이라면 모델이 종속변수를 전혀 설명하지 못한다는 의미
5. 고급 회귀 기법 - Lasso & Ridge Regression
- 선형 회귀에 규제(Regularization) 항을 추가하여 과적합을 방지
☑️ Ridge(릿지) 회귀

- 가중치 제곱합(L2 Norm)을 페널티로 추가
- 효과: 가중치가 너무 커지지 않도록 방지(가중치 값을 부드럽게 줄임)
☑️ Lasso(라쏘) 회귀
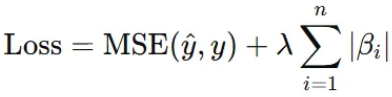
- 가중치 절댓값합(L1 Norm)을 페널티로 추가
- 효과: 가중치를 0으로 만들어 변수 선택(Feature Selection) 효과
☑️ 릿지회귀 & 라쏘회귀 코드
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, Lasso
from sklearn.metrics import mean_squared_error, r2_score
# 1. 데이터 로드
housing = fetch_california_housing()
X = housing.data
y = housing.target
print(X.shape)
print(y.shape)# 2. 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)# 3. Ridge 회귀
# alpha=1.0 (규제 세기) 는 필요에 따라 조정 가능
ridge_reg = Ridge(alpha=1.0, random_state=42)
ridge_reg.fit(X_train, y_train)# 예측
y_pred_ridge = ridge_reg.predict(X_test)
# 성능 평가
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
r2_ridge = r2_score(y_test, y_pred_ridge)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[Ridge 회귀 결과]")
print(" 가중치(coefficient):", ridge_reg.coef_)
print(" 절편(intercept):", ridge_reg.intercept_)
print(" MSE:", mse_ridge)
print(" R^2 점수:", r2_ridge)
print("평균 비율 오차 : ", MPE(y_test, y_pred_ridge))
print()
# 4. Lasso 회귀
# alpha=0.1 정도로 조금 낮춰 볼 수도 있음 (기본값 1.0)
# alpha가 너무 크면 가중치가 0이 되어 과소적합 위험이 있습니다.
lasso_reg = Lasso(alpha=0.1, random_state=42, max_iter=10000)
lasso_reg.fit(X_train, y_train)# 예측
y_pred_lasso = lasso_reg.predict(X_test)
# 성능 평가
mse_lasso = mean_squared_error(y_test, y_pred_lasso)
r2_lasso = r2_score(y_test, y_pred_lasso)
# 평균 비율 오차
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
print("[Lasso 회귀 결과]")
print(" 가중치(coefficient):", lasso_reg.coef_)
print(" 절편(intercept):", lasso_reg.intercept_)
print(" MSE:", mse_lasso)
print(" R^2 점수:", r2_lasso)
print("평균 비율 오차 : ", MPE(y_test, y_pred_lasso))
☑️ 코드 해설
- 데이터 로드
- fetch_california_housing() 함수로 캘리포니아 주택 가격 예측용 데이터를 불러온다.
- X는 특성 행렬(8개 특성), y는 주택 가격(타겟)
- 학습/테스트 데이터 분리
- train_test_split을 이용해 전체 데이터의 80%를 학습용, 20%를 테스트용으로 분리
- random_state=42로 고정하여 재현 가능성을 높인다.
- Ridge 회귀
- L2 규제항을 포함하는 Ridge 모델
- alpha가 클수록 규제 강도가 세어져, 모델 가중치(계수)들의 크기를 더욱 제약
- 학습 후, 예측 결과에 대해 MSE와 R^2 점수를 계산
- Lasso 회귀
- L1 규제항을 사용하는 Lasso 모델
- alpha가 클수록 일부 가중치가 정확히 0으로 수렴(특성 선택 효과).
- 마찬가지로 MSE, R^2를 통해 성능을 평가
총 정리
1. 회귀 모델은 연속형 결과 변수를 예측하는 데 사용한다.
2. 선형 회귀는 가장 기본적인 형태지만, 데이터의 패턴이 비선형일 경우 다항 회귀 등을 고려해야 한다.
3. 규제(Regularization) 기법을 활용한 모델(Lasso, Ridge)은 가중치를 규제하여 과적합을 방지한다.
4. 앙상블 기법(Gradient Boosting, XGBoost 등)을 사용하는 경우 복잡한 비선형 패턴을 더 잘 포착할 수 있다 (추후 배울 내용)
5. 모델의 성능 평가는 MAE, RMSE, R² 등 다양한 지표를 통해 진행한다.
'머신러닝' 카테고리의 다른 글
| 머신러닝(클러스터링) (2) | 2025.07.08 |
|---|---|
| 머신러닝(앙상블 기법) (0) | 2025.07.07 |
| 머신러닝(분류) (1) | 2025.07.04 |
| 머신러닝(데이터 전처리) (2) | 2025.07.02 |
| 머신러닝(머신러닝이란 ?) (0) | 2025.07.01 |



