
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 이상탐지
- 내일배움캠프#til#파이썬#python
- 통계학공부
- 딥러닝
- 라이브 세션
- 내일배움캠프#til#데이터 리터러시
- 머신러닝
- 제1종오류
- 통계학
- #내일배움캠프 #사전캠프 #til #sql
- 다중검정
- vscode
- 차원축소
- 책
- 내일배움캠프#til#sqld#eda#데이터리터러시
- 가설검정
- 이상치 제거
- t검정
- 내일배움캠프#til#sqld
- 내일배움캠프#til#파이썬#python#통계학
- 통계
- 내일배움캠프#til#파이썬#python#전처리
- 통계101x데이터분석
- 내일배움캠프#til#sql
- 데이터
- 데이터분석
- 제2종오류
- A/B테스트
- 카이제곱검정
- Ai
- Today
- Total
Ming's Life
머신러닝(데이터 전처리) 본문
1. 오늘 학습 키워드
- 머신러닝 기초
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
1. 데이터 전처리 개요
- 원시(raw) 데이터에서 불필요하거나 손실(노이즈)이 있는 부분을 처리하고, 분석 목적에 맞는 형태로 만드는 과정
☑️ 필요성
1. 모델 정확도 및 신뢰도 향상
2. 이상치나 결측치가 많은 상태로 학습하면 예측 성능이 크게 떨어짐
3. 효율적인 데이터 분석과 모델 훈련을 위해 필수적인 단계
☑️ 마케팅 사례
- 온라인 설문이나 쿠폰 사용 정보가 중간에 누락되거나, 특정 채널(이메일·SNS·오프라인)에서 전송된 쿠폰 수 확인 불가한 경우 결측값 발생
- 광고 클릭률 중 특정 상품의 노출수/클릭수가 월등히 높아 평균을 왜곡, 혹은 이벤트가 끝나자마자 조회수가 급감하는 경우 이상치 기록
- 고객 이탈 예측 시 ‘이탈 고객’ 비율이 매우 적은 경우, 특정 광고 캠페인 전환 성공/실패 비율의 극단적 차이가 발생하는 경우 불균형 발생
2. 결측치 처리
☑️ 결측치 발생 원인
- 센서 고장, 측정 오류, 환경적 문제 등
- 사람이 수기로 입력하는 경우 누락
☑️ 결측치 처리 기법
1. 삭제(Removal)
: 결측치가 있는 행(row) 또는 열(column)을 제거
→ 간단하지만 데이터 손실이 발생
→ 결측치가 전체 데이터에서 매우 소수일 때 적합
2. 대체(Imputation)
: 평균 또는 중앙값으로 대체
→ 수치형 데이터에서 많이 사용, 데이터 분포 왜곡이 비교적 적음
: 최빈값으로 대체
→ 범주형 데이터에서 사용
: 예측 모델로 대체
→ 회귀/분류 모델을 이용해 결측값을 예측
☑️ 마케팅 예시
- 캠페인 반응(클릭률, 전환율) 데이터의 경우
→ 온라인 광고나 캠페인 전환율이 일시적으로 누락된 경우, 인접 기간(예: 전일, 전주 동일 요일) 데이터 기반으로 보정
→ 시점별로 전환 흐름이 비교적 일정하거나 특정 패턴(요일 효과 등)이 있다면, 이동평균으로 추정 가능
- 고객 설문/프로필 정보의 경우
→ 나이, 지역, 성별 등의 간단한 인구통계학적 정보는 최빈값·중앙값으로 대체 가능 → 그룹(클러스터)의 대표값으로 대체 (결측값이 속한 클러스터의 평균, 중앙값 등을 사용)
- 정기적으로 누락되는 채널/시점 데이터의 경우
→ 특정 채널 또는 시간대에 반복적으로 누락된다면, 시스템(로그 수집, 쿠폰 트래킹 등)을 개선해 재발을 방지
→ 결측이 반복되는 구간은 유사 채널 지표로 추정
☑️ 결측치 처리 코드
# 2) 결측치 제거 (결측이 하나라도 있으면 해당 행을 제거)
df_drop = df.dropna()
df_drop# 3) 평균값으로 대치
df_mean = df.copy()
df_mean = df_mean.fillna(df_mean.mean(numeric_only=True))
df_mean# 4) 중앙값으로 대치
df_median = df.copy()
df_median = df_median.fillna(df_median.median(numeric_only=True))
df_median# 5) 최빈값으로 대치
# - DataFrame의 mode()는 각 열별로 최빈값을 반환합니다.
# - mode() 결과가 여러 개(동률)일 경우 첫 번째 행의 값을 취합니다.
df_mode = df.copy()
print(df_mode.mode()) # 확인용
mode_values = df_mode.mode().iloc[0] # 첫 번째 행(가장 상위 mode)만 취함
df_mode = df_mode.fillna(mode_values)
df_mode
☑️ 코드 해설
- df.copy()
- 원본 df를 그대로 복사하여 새로운 변수에 할당합니다.
- 이렇게 하는 이유는 결측치를 채워넣은 결과(DataFrame)가 원본 데이터에 영향을 주지 않도록 별도의 사본을 만들어 작업하기 위함입니다.
- df_mean = df_mean.fillna(df_mean.mean(numeric_only=True))
- fillna()는 결측치(NaN)를 주어진 값으로 대체하는 메서드입니다.
- df_mean.mean(numeric_only=True)는 각 열(column)별 평균값을 계산합니다.
- numeric_only=True는 숫자형 열에 대해서만 평균을 계산하겠다는 옵션입니다 </aside>
- df_median = df_median.fillna(df_median.median(numeric_only=True))
- df_median.median(numeric_only=True)는 각 열별 중앙값(median)을 계산합니다.
- fillna()에 이 중앙값을 전달해, 결측값을 열별 중앙값으로 대체합니다. </aside>
- df_mode.mode()는 각 열(column)마다 최빈값(mode)을 찾습니다.
- df_median.median(numeric_only=True)는 각 열별 중앙값(median)을 계산합니다.
- fillna()에 이 중앙값을 전달해, 결측값을 열별 중앙값으로 대체합니다. </aside>
3. 이상치 탐지 및 제거
☑️ 이상치(Outlier) 정의
- 정상 범주에서 크게 벗어나는 값
- 장비 오작동, 환경적 특이 상황 등 원인이 다양함
☑️ 탐지 기법
1. 통계적 기법 (3σ Rule)
: 데이터가 정규분포를 따른다고 가정하고, 평균에서 ±3σ(표준편차) 범위를 벗어나는 값을 이상치로 간주
: 직관적이고 간단하나, 정규성 가정이 틀릴 수 있음
2. 박스플롯(Boxplot) 기준
: 사분위수(IQR = Q3 - Q1)를 이용해 ‘Q1 - 1.5×IQR’, ‘Q3 + 1.5×IQR’를 벗어나는 데이터를 이상치로 간주
: 분포 특성에 영향을 적게 받는 장점
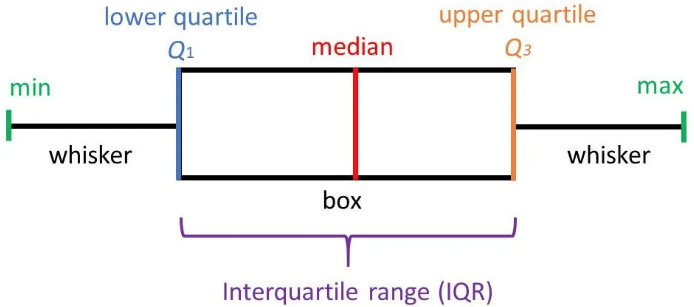
3. 머신러닝 기반
: 이상치 탐지 알고리즘 (Isolation Forest, DBSCAN 등)
: 복합적 패턴을 고려할 수 있음
☑️ 처리 기법
1. 이상치를 단순 제거(필요하다면)
2. 이상치 값을 조정(클리핑, Winsorizing 등)
3. 별도로 구분하여 모델에서 제외하거나, 다른 모델(이상치 예측 모델)로 활용
☑️ 마케팅 예시
- 어떤 광고 캠페인에서 클릭률(CTR)이 다른 캠페인에 비해 극단적으로 높아, 평균 분석을 왜곡하는 경우가 이상치
- 고객 구매 이력에서 특정 기간에 평소와 전혀 다른 과도한 소비(장바구니 금액 폭증)가 포착되면 마케팅 분석에서 이상치로 분류 가능
☑️ 이상치 제거 코드 예시
# 이상치 제거 (간단하게 박스플롯 기준 적용 예시)
Q1 = df['sensor_value'].quantile(0.25)
Q3 = df['sensor_value'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df = df[(df['sensor_value'] >= lower_bound) & (df['sensor_value'] <= upper_bound)]
df
4. 정규화 / 표준화
☑️ 왜 필요한가 ?
1. 모델(특히 거리 기반 알고리즘, 딥러닝 등)에 따라 특정 변수의 스케일이 크게 영향을 미칠 수 있음
2. 센서 A는 값 범위가 0~1000, 센서 B는 값 범위가 0~1이라면, A가 모델에 더 큰 영향을 줌
☑️ 정규화
1. MinMaxScaler
: 모든 값을 0과 1 사이로 매핑
: ex)

2. 특징
: 값의 스케일이 달라도 공통 범위로 맞출 수 있음.
: 딥러닝(신경망), 이미지 처리 등에서 입력값을 0~1로 제한해야 하거나, 각 특성이 동일한 범위 내 있어야 하는 경우 자주 사용.
: 거리 기반 알고리즘(유클리디안 거리 사용)이나, 각 특성의 범위를 동일하게 맞춤으로써 계산 안정성을 높이고 싶을 때.
: 최소값·최대값이 극단값(Outlier)에 민감. 만약 극단치가 있으면 대부분의 데이터가 [0, 1] 구간 내부 한쪽에 치우침.
: 새로운 데이터가 기존 최대값보다 커지거나, 최소값보다 작아지는 경우, 스케일링 범위를 벗어날 수 있어 재학습하거나 다른 처리가 필요.
☑️ 표준화
1. StandardScaler
: 평균을 0, 표준편차를 1로 만듦
: ex)

2. 특징
: 분포가 정규분포에 가깝게 변형됨
: 평균이 0, 표준편차가 1로 맞춰지므로, 정규분포 가정을 사용하는 알고리즘(선형회귀, 로지스틱회귀, SVM 등)에 자주 쓰임.
: 변환된 값들이 이론적으로 -∞ ~ +∞ 범위를 가질 수 있다.
: 데이터가 특정 구간([0, 1] 등)에 고정되지는 않는다.
: 데이터 분포가 심하게 치우쳐 있으면, 평균과 표준편차만으로는 충분한 스케일링이 되지 않을 수 있다(로그 변환, RobustScaler 등 추가 고려)
☑️ 정규화/표준화 코드
from sklearn.preprocessing import MinMaxScaler
# 정규화
# 스케일링을 적용할 컬럼만 선정
cols_to_scale = ['impressions', 'clicks', 'conversions', 'cost', 'revenue']
# MinMaxScaler 객체 생성(기본 스케일: [0,1])
minmax_scaler = MinMaxScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_minmax_scaled = pd.DataFrame(minmax_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_minmax_scaled.max())
print(df_minmax_scaled.min())
df_minmax_scaled
from sklearn.preprocessing import StandardScaler
# 표준화
# StandardScaler 객체 생성
standard_scaler = StandardScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_standard_scaled = pd.DataFrame(standard_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_standard_scaled.mean())
print(df_standard_scaled.std())
df_standard_scaled
☑️ 코드 해설
MinMaxScaler()
: fit_transform(df[['칼럼이름']]) 호출
: MinMaxScaler()를 만들어서 scaler라는 이름으로 할당합니다.
1️⃣ fit: 열을 살펴 최솟값과 최댓값을 찾습니다.
2️⃣ transform: 찾은 최소·최대값으로 각 데이터를 0~1 범위로 바꿉니다.
StandardScaler()
: StandardScaler()를 만들어서 standard_scaler라는 이름으로 할당합니다.
: fit_transform(df[['칼럼이름']]) 호출
1️⃣ fit: 열의 평균과 표준편차를 구합니다.
2️⃣ transform: 각 값을 (x - 평균) / 표준편차로 변환해, 평균 0, 표준편차 1인 분포를 만듭니다.
5. 불균형 데이터 처리
☑️ 불균형 데이터란 ?
- 정상 99%, 불량 1%처럼 한 클래스가 극도로 적은 경우
☑️ 문제점
- 모델이 극도로 적은 클래스를 거의 예측하지 못할 가능성이 큼(편향 발생)
☑️ 해결 기법
1. Oversampling
📚 Random Oversampling
: 소수 클래스의 데이터를 단순 복제하여 개수를 늘림
📚 SMOTE(Synthetic Minority Over-sampling Technique)
: 소수 클래스를 "무작정 복사"만 하는 게 아니라, “비슷한” 데이터들을 서로 섞어서(Interpolation) 새로운 데이터 생성
: 즉, 소수 클래스(ex: 스팸) 안에서 가까운 데이터 둘(혹은 몇 개)을 고르고, 그 사이에 새 데이터 포인트를 만들어내어, 소수 클래스의 다양한 예시를 가상으로 늘리는 기법
예시로 생각해보기
→ 오렌지(소수 클래스)와 사과(다수 클래스)가 있는 과일 바구니를 떠올려보자.
→ 사과는 90개, 오렌지는 10개뿐이면, 사과가 훨씬 많다.
→ "오렌지를 조금 더 만들어서(복사)" 갯수를 맞출 수도 있지만, 그러면 똑같은 오렌지가 여러 개 생길 뿐, 다양성이 없다.
→ SMOTE는 어떻게 하느냐면,
“모양이나 맛이 비슷한 두 오렌지를 고른 다음, 그 중간 정도 되는 새로운 오렌지를 상상해서 만들어낸다” 같은 느낌이다.
이렇게 하면 기존 오렌지랑 똑같지도 않고, 완전히 엉뚱하지도 않은 새 오렌지를 얻을 수 있다.
2. Undersampling
: 다수 클래스 데이터를 줄이는 방식
: 데이터 손실 위험이 있지만, 전체 데이터 균형을 맞출 수 있음
3. 혼합 기법
: SMOTE와 언더샘플링을 적절히 섞어서 사용
☑️ 불균형 데이터 처리 코드
from imblearn.over_sampling import SMOTE
# 불균형 데이터 처리 (SMOTE)
X = df.drop('defect', axis=1) # 결측치 처리, 이상치 제거, 인코딩 등 사전 처리 후
y = df['defect']
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)
☑️ 코드 해설
X = df.drop('defect', axis=1)
: df 데이터프레임에서 defect 컬럼(레이블)을 제외한 나머지를 X(특징 행렬)로 사용한다.
: 이때, 이미 결측치 처리, 이상치 제거, 범주형 인코딩 등의 사전 전처리를 마쳤다고 가정한다.
y = df['defect']
: defect 컬럼을 타겟(레이블)으로 설정한다.
: 예) defect가 1이면 제품 결함 있음, 0이면 결함 없음 등.
smote = SMOTE(random_state=42)
: SMOTE 객체를 생성한다.
: SMOTE는 소수 클래스(예: 결함 사례)가 너무 적을 때, 기존 소수 클래스 데이터들을 바탕으로 유사한 새로운 예시를 만들어 데이터 개수를 늘려주는 기법이다.
: random_state=42는 재현성(코드 실행 시 동일 결과)을 위해 난수 시드를 고정하는 역할이다.
X_res, y_res = smote.fit_resample(X, y)
: fit_resample을 통해 SMOTE 알고리즘이 X, y를 바탕으로 소수 클래스 데이터를 자동 생성합니다.
: 결과적으로, 오버샘플링된 X_res, y_res에는 클래스 불균형이 개선된(1:1에 가깝거나 원하는 비율이 된) 상태가 됩니다.
6. 범주형 데이터 변환
☑️ 원-핫 인코딩 (One-Hot Encoding)
- 범주형 변수를 각각의 범주별로 새로운 열로 표현, 해당 범주에 해당하면 1, 아니면 0
- ex) 색상(‘Red’, ‘Blue’, ‘Green’) → ‘Red=1,Blue=0,Green=0’ / ‘Red=0,Blue=1,Green=0’ / …
- 장점: 범주 간 서열 관계가 없을 때 사용하기 좋음
- 단점: 범주가 매우 많으면 차원이 커짐
☑️ 레이블 인코딩 (Lable Encoding)
- 범주를 숫자로 직접 맵핑(‘M’=0, ‘L’=1, ‘XL’=2 등)
- 단순하지만, 모델이 숫자의 크기를 서열 정보로 잘못 해석할 수 있음
☑️ 원 - 핫 인코딩 코드
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
data_size = 10
np.random.seed(42)
labels = ['apple', 'banana', 'cherry']
random_labels = np.random.choice(labels, data_size)
df = pd.DataFrame({
'id': range(1, data_size + 1),
'label': random_labels,
'value': np.random.randint(1, 100, data_size),
'another_feature': np.random.choice(['A', 'B'], data_size) # 또 다른 범주형 변수
})
dfdf['label'].unique()# 범주형 변수 변환 (원-핫 인코딩 예시)
df = pd.get_dummies(df, columns=['label'])
☑️ 코드 해설
→열의 범주들(A, B, C 등)을 각각 별도 열로 만들어, 해당하는 행에는 1, 그렇지 않은 행에는 0을 넣어줍니다.
☑️ 레이블 인코딩 코드
# 범주형 변수 변환 (레이블 인코딩 예시)
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df["label"] = encoder.fit_transform(df["label"])
df
☑️ 코드 해설
- from sklearn.preprocessing import LabelEncoder
- 사이킷런(sklearn) 라이브러리에서 LabelEncoder 클래스를 불러옵니다.
- LabelEncoder는 문자열이나 범주형 데이터를 정수로 변환하기 위한 클래스입니다.
- encoder = LabelEncoder()
- LabelEncoder를 인스턴스화하여 encoder라는 이름으로 객체를 생성합니다. </aside>
- df["label"] = encoder.fit_transform(df["label"])
- df["label"] 열(column)을 fit_transform 메서드에 전달하여,
- fit: 데이터에 등장하는 범주를 학습
- transform: 학습한 매핑에 따라 데이터를 정수로 변환
- 변환된 결과(정수 라벨)를 다시 df["label"]에 덮어쓰기합니다.
- 예를 들어, ["red", "blue", "blue", "green"] 같은 문자열 범주가 존재하면,
- "blue" → 0
- "green" → 1
- "red" → 2와 같이 매핑될 수 있습니다(실제 순서는 데이터에 따라 달라집니다). </aside>
- df["label"] 열(column)을 fit_transform 메서드에 전달하여,
7. 피처 엔지니어링 개요
- 모델 성능 향상을 위해 기존 데이터를 변형, 조합하여 새로운 특성(피처)을 만드는 작업
☑️ 중요성
1. 복잡한 데이터 구조 안에 존재하는 패턴을 효과적으로 추출해 모델이 쉽게 학습하게 함
2.
1) 제조업에서는 센서 데이터 간 시계열적·물리적 관계를 반영하는 경우가 많음
2) 금융에서의 데이터는 고객 신용도, 거래내역, 시장 지표 등 복잡하고 다양한 변수를 포함하는 경우가 많음
3) 마케팅에서는 고객 행동 데이터(클릭, 구매 기록, 웹사이트 체류 시간 등)와 고객 특성 데이터(나이, 지역, 관심 분야 등)를 통합해 피처 를 만들어야 효과적인 캠페인 타깃팅, 고객 세분화, 개인화 추천이 가능한 경우가 많음
8. 피처 엔지니어링 실습 예시
☑️ 파생 변수 생성
1. 날짜 파생 변수
: ex) 측정 시간이 ‘2025-02-24 10:35:00’이라면, ‘월(2)’, ‘요일(월=1)’, ‘시(10)’, ‘주말여부(0/1)’ 등으로 분해
2. 수치형 변수 조합
: ex) ‘온도’와 ‘습도’가 있을 때, 새로운 피처 ‘온도×습도(TEMP×HUMID)’를 추가
: 두 변수의 상호작용이 불량 발생에 영향을 줄 수 있음
3. 로그 변환, 제곱근 변환 등
: 분포가 매우 치우친 변수(오른쪽 꼬리가 긴 경우)에 로그 변환을 적용하여 정규성에 가까워지도록 조정
import pandas as pd
import numpy as np
np.random.seed(42) # 재현성을 위한 시드 고정
# 10개 데이터 샘플 생성
data_size = 10
# 날짜/시간 컬럼(예시)
dates = pd.date_range(start="2023-01-01", periods=data_size, freq='D')
# 온도(°C) : 15 ~ 35 사이 정수
temperature = np.random.randint(15, 36, size=data_size)
# 습도(%) : 30 ~ 90 사이 정수
humidity = np.random.randint(30, 91, size=data_size)
df = pd.DataFrame({
'date': dates,
'temperature': temperature,
'humidity': humidity
})
df# 피처 엔지니어링 (온도와 습도 간 상호작용)
df['temp_humid_interaction'] = df['temperature'] * df['humidity']
df☑️ 변수 선택 (Feature Selection)
- 상관관계
- 두 변수 간 상관도가 높은 상황인 경우 다중공선성 의심. 중복 정보가 클 수 있으므로, 하나만 남기거나 둘 다 제거 고려
- 📚 다중공선성이란?
- 회귀분석(집값 예측, 매출 예측 등)을 할 때, 여러 설명 변수(독립 변수)를 사용
- 그런데 이 변수들이 서로 너무 비슷한 정보를 담고 있어 (즉, 서로 강하게 상관이 있어) 모델이 헷갈리는 문제가 생김
- 이런 다중공선성(multicollinearity) 문제는 회귀계수(모델 파라미터)의 의미 해석과 모델 안정성을 해침
- ex) 집 크기(㎡)와 방 개수가 거의 정비례한다면, 둘 다 넣었을 때 겹치는 정보가 많아진다.
- 예시로 생각해보기
- "방 개수"와 "평수(㎡)"라는 두 변수를 예
- 방이 5개면 평수도 대체로 넓고, 1개면 대체로 좁다(둘은 서로 높은 상관 관계).
- 둘 다 회귀분석에 넣으면 모델 입장에서 "비슷한 정보가 두 번 들어온 셈"이라,어떤 변수가 집값에 얼마나 영향을 주는지(독립적 기여도)를 구분하기 어려워집니다.
- 이런 경우, VIF가 높게 나타납니다.
- VIF
- 회귀분석에서 다중공선성 문제를 파악할 때 사용
- VIF는 어떤 변수 하나가, 다른 변수들과 얼마나 겹치는지(상관이 큰지) 수치로 보여주는 지표
- VIF가 일정 기준(예: 10 이상)을 넘으면 해당 변수를 제거하거나 비슷한 변수들을 합치는(변환) 등의 방법으로 문제를 해결
- 모델 기반 중요도(Feature Importance)
- 트리 기반 모델(랜덤 포레스트, XGBoost 등)을 훈련 후 중요도가 낮은 변수를 제거
☑️ 변수 간 상호작용 추가
- 다항식/교차 항 생성
- ex) 2차 다항식(Quadratic Features)
- 제조 공정에서 온도, 압력, 속도 등이 곱해져야 비로소 의미가 생기는 경우가 많음
총 정리
1. 결측치와 이상치를 올바르게 처리하는 것은 모델의 기초
2. 불균형 데이터 문제를 해결하지 않으면 소수 클래스(불량)을 놓칠 수 있음
3. 범주형 변수는 원-핫 인코딩, 레이블 인코딩 등으로 적절히 변환
4. 피처 엔지니어링을 통해 데이터에서 추가 정보(패턴)을 추출하거나, 중요하지 않은 변수는 제거해 모델 효율과 성능을 높임
💡추가 팁
: 전처리와 피처 엔지니어링 과정에서의 모든 선택(결측치 처리 방식, 이상치 제거 기준 등)은 도메인 지식과 데이터 탐색(EDA) 결과를 함께 고려해야 함
: 각 단계별로 간단한 모델을 시험적으로 훈련해보고 성능 변화를 체크하는 것이 좋음
'머신러닝' 카테고리의 다른 글
| 머신러닝(클러스터링) (2) | 2025.07.08 |
|---|---|
| 머신러닝(앙상블 기법) (0) | 2025.07.07 |
| 머신러닝(분류) (1) | 2025.07.04 |
| 머신러닝(회귀) (2) | 2025.07.03 |
| 머신러닝(머신러닝이란 ?) (0) | 2025.07.01 |



