
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Ai
- #내일배움캠프 #사전캠프 #til #sql
- 내일배움캠프#til#파이썬#python
- 내일배움캠프#til#sqld
- 딥러닝
- 이상탐지
- 통계
- 카이제곱검정
- t검정
- 라이브 세션
- A/B테스트
- 다중검정
- vscode
- 내일배움캠프#til#sql
- 제2종오류
- 통계학공부
- 이상치 제거
- 가설검정
- 통계학
- 내일배움캠프#til#데이터 리터러시
- 차원축소
- 머신러닝
- 통계101x데이터분석
- 책
- 데이터분석
- 내일배움캠프#til#sqld#eda#데이터리터러시
- 내일배움캠프#til#파이썬#python#통계학
- 데이터
- 내일배움캠프#til#파이썬#python#전처리
- 제1종오류
- Today
- Total
Ming's Life
머신러닝(머신러닝이란 ?) 본문
1. 오늘 학습 키워드
- 머신러닝 기초
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
1. 머신러닝이란 ?
- 컴퓨터가 인간의 개입 없이 데이터를 학습하여 패턴을 찾아내고, 새로운 데이터에 대해 예측이나 분류를 수행하는 기술
☑️ 머신러닝의 3대 요소
1. 데이터 : 데이터가 참고하는 정보의 모음
2. 알고리즘(Algorithm) : 문제를 해결하기 위해 순서대로 처리하는 방법이나 규칙
3. 컴퓨팅 파워(Computing Power) : 컴퓨터가 얼마나 빠르고 많이 일(연산)을 할 수 있는지 나타내는 능력치
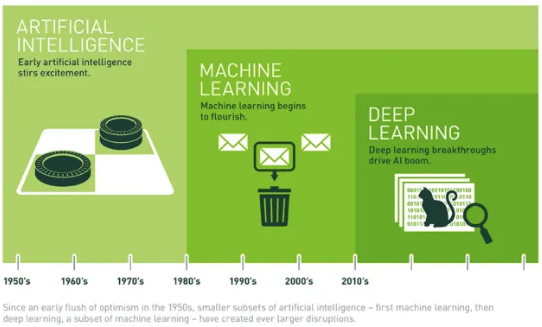
☑️ 머신러닝, AI, 딥러닝의 관계
- 인공지능(AI)
- 사람의 지능적인 작업을 기계가 수행하도록 만드는 광범위한 개념
- 머신러닝
- AI를 실현하기 위한 방법 중 하나로, 데이터로부터 특징이나 규칙을 찾아내서 학습 하는 것
- ex) 스팸 메일에는 특정 단어나 형태가 자주 등장하는 공통점(패턴)이 있을 수 있는데 이를 자동으로 스팸으로 분류
- 딥러닝(Deep Learning)
- 머신러닝의 하위 분야로, 사람의 뇌신경을 본 떠 만든 인공신경망으로 이루어져 있음
- 인공신경망을 여러 겹 쌓아서 복잡한 정보를 학습할 수 있음
- ex) 오늘날 많이 유명한 모델들이 여기에 속함 : ChatGPT, 알파고, 알파스타, DALL-E
2. 머신러닝의 역활 및 중요성
☑️ 대량의 데이터 처리와 분석
- 현대 사회는 매순간 엄청난 양의 데이터를 생성
- 대규모 데이터를 빠르고 정확하게 분석하여, 복잡한 상관관계를 발견하고 예측
- 기존 방식으로는 처리하기 어려웠던 빅데이터 활용 가능
- ex) SNS에 쏟아지는 게시글, 대형 쇼핑몰의 상품 거래 기록 등
📚 빅데이터란? → 일반적인 방법으로는 저장·분석하기 힘들 만큼 방대한 양의 데이터
☑️ 다양한 산업 분야에서의 활용
1. 제조업
: 센서 데이터 수집 → 설비 이상 징후 예측, 품질 불량 예측
: 자동화된 공정 제어 및 유지 보수 비용 절감
2. 금융
: 신용카드 사기 거래 탐지, 대출 리스크 평가
: 알고리즘 트레이딩(주식 자동 매매)
3. 헬스케어
: 질병 진단(영상, 유전자 분석), 환자 상태 예측
4. 마케팅
: 고객 세분화, 구매 패턴 분석, 타겟 마케팅
5. 자율주행
: 카메라, 라이다 등을 통한 실시간 도로 상황 분석 → 의사결정
☑️ 마케팅 예시
- 고객 세분화(Customer Segmentation) & 페르소나(Persona) 도출
- 고객 데이터를 기반으로 인구통계학적 정보(나이, 지역, 직업 등), 구매 이력, 선호 카테고리 등을 고려하여 유사한 행동양식을 보이는 집단을 군집화
- ex) ‘20대 여성 / 운동 좋아함 / 건강식품 구매 잦음’ 같은 그룹
- 추천 시스템(Recommendation System)
- 사용자가 좋아하거나 흥미로워할 만한 상품·콘텐츠를 자동으로 골라주는 시스템
- ex) 유튜브에서 시청 이력을 바탕으로 ‘다음에 볼 만한 영상’을 추천해주는 기능
- 사용자가 좋아하거나 흥미로워할 만한 상품·콘텐츠를 자동으로 골라주는 시스템
- 마케팅 캠페인 성과 예측(Predictive Marketing Analytics)
- 과거 캠페인 데이터(노출 수, 클릭 수, 전환율 등)와 고객 반응 데이터를 바탕으로, 향후 캠페인의 성과(전환율, 매출 기여도)를 예측
- 고객 생애 가치(LTV) 예측
- 한 명의 고객이 우리 회사와 거래하는 동안 얼마나 많은 수익을 가져다줄지를 예상하는 고객 생애 가치(LTV)를 예측
3. 머신러닝 vs 기존 통계 분석
☑️ 가설 검증 vs 예측 성능
- 통계 분석
- 가설 검증, 추론(예: "이 변수와 저 변수 사이에 유의한 관계가 있는가?")
- 주로 "왜?"라는 질문에 집중
- 머신러닝
- 예측(얼마나 정확하게 미래나 미지의 데이터를 예측할 수 있는가)
- "얼마나 잘?"에 집중(정확도, 재현율 등)
☑️ 데이터가 많아질수록
- 통계
- 표본 수가 커지면 더 정교한 추론이 가능하지만, 일반적으로 가설 자체는 사람이 세움
- 머신러닝
- 데이터가 많을수록 학습에 유리하며, 더 좋은 모델을 만들 수 있음
4. 머신러닝의 종류

☑️ 지도학습 (Supervised Learning)
- 우리가 맞다고 알고 있는 결과값을 정답값(레이블) -> 이러한 정답값이 있는 데이터를 학습하는 방식
- 예를 들어, 고양이 사진에는 '고양이'라는 정답(레이블)을 붙여서, 컴퓨터가 어떤 이미지가 고양이인지 학습 가능
1. 분류(Classification)
: 어느 그룹에 속하는지를 결정
: ex) 이메일이 스팸인지 아닌지, 은행 대출 상환 가능 여부
2. 회귀(Regression)
: 숫자로 된 결과를 예측
: ex) 주택 가격 예측, 주가 예측
☑️ 비지도학습 (Unsupervised Learnig)
- 레이블 없이 데이터 패턴을 스스로 찾음
1. 군집화(Clustering)
: 성향이 비슷한 사람이나 사물을 자동으로 묶어내는 기법
: ex) 고객 군집 분석, 문서 토픽 분석
2. 차원 축소(Dimensionality Reduction)
: 데이터의 특징(변수)이 너무 많아서 복잡한 데이터를, 핵심 정보만 남기고 압축하는 기법
: ex) 수백 가지 지표가 있는 데이터를 2~3개의 핵심 지표로 요약

☑️ 강화학습 (Reinforcement Learning)
- 에이전트가 환경과 상호작용하며 보상(Reward)을 최대화하도록 학습
📚 환경이란? → 에이전트가 움직이고 상호작용하는 무대
📚 보상이란? → 에이전트가 잘했을 때 얻는 점수(칭찬)나, 잘못했을 때 받는 벌점 같은 개념
📚 에이전트란? → 학습을 수행하는 주인공, 게임으로 치면 플레이어, 로봇으로 치면 로봇 자체가 에이전트
- ex) 알파고(바둑), 로보틱스, 게임 AI
- 시뮬레이션 환경에서 시도-오류를 반복하며 **가장 높은 보상을 보장해주는 행동 규칙(전략)**을 학습
5. 머신러닝 모델링 프로세스
- 머신러닝 프로젝트는 단순히 모델만 잘 만든다고 끝나지 않는다.
- 데이터 수집부터 배포까지 전체 흐름을 이해하는 것이 매우 중요하다.
☑️ 데이터 수집
- 웹 크롤링, 센서 측정, 설문조사, DB 추출 등 다양한 방법
- 양질의 데이터 확보가 프로젝트의 성패를 좌우
- ex) 제조업에서는 공정 라인에 설치된 IOT 센서에서 데이터 지속 수집
☑️ 전처리 (Preprocessing)
1. 결측치 처리
: 결측치란 데이터 표에서 일부 셀이 비어 있는 상태
: 빈 칸을 평균이나 가장 빈도가 높은 값으로 대신 채우거나, 필요하면 빼고(삭제) 분석
2.이상치 처리
: 대부분의 데이터 범위에서 심하게 벗어난 값을 해결
ex) 사람 몸무게 데이터가 대개 50~100kg인데, 500kg으로 기록된 경우 등
3. 스케일링 ( 정규화 / 표준화 )
: 각기 다른 단위를 쓰는 데이터를 비슷한 수준으로 맞춰주는 작업
ex) 키는 150~180의 범위를 가지고 있고 몸무게는 50~100의 범위를 가지고 있어서 값의 크기가 다른데, 몸무게와 키 모두 0~1 범위로 바꾸면, 머신러닝 알고리즘이 두 값을 더 공평하게 다룰 수 있다.
4. 범주형 변환
: 글자로 된 정보를 숫자로 바꿔주는 과정
📚 원-핫 인코딩 이란? → 해당 범주에 속하면 1, 아니면 0을 넣는 방식
- ‘빨강·초록·파랑’이라는 세 범주가 있으면
- 빨강 = (1,0,0), 초록 = (0,1,0), 파랑 = (0,0,1)
📚 레이블 인코딩 예시 → 순서대로 숫자를 부여
- M=0, L=1, XL=2 …
- 다만, 숫자에 순위 의미가 생겨버릴 수 있어서 주의가 필요
☑️ 모델링 (Modeling)
- 지도학습의 경우 분류/회귀 알고리즘 선택 (ex: 로지스틱 회귀, 랜덤 포레스트, XGBoost 등)
- 비지도학습의 경우 클러스터링/차원 축소 알고리즘 선택 (ex: K-Means, PCA 등)
☑️ 성능 평가 (Evaluation)
1. 분류
: Accuracy, Precision, Recall, F1-score, ROC-AUC 등
2. 회귀
: MAE, RMSE, R² 등
3. 비지도(군집)
: 실루엣 계수 등
성능 평가에 대해서는 추 후 자세히 살펴보기로 한다.
6. 윤리적 이슈 & 데이터 편향(Bias)
☑️ 데이터 편향 (Data Bias)
- 학습 데이터에 편향된 샘플이 많으면, 모델도 그 편향을 그대로 학습
- ex) 인종·성별 분포가 편향된 데이터 → 차별적 의사결정
☑️ 윤리적 책임 (Responsible AI)
- 편향을 줄이기 위한 데이터 균형화
- 민감 정보 보호(개인정보 비식별화, GDPR 등 법적 규제 준수)
- ex) 인종·성별 분포가 편향된 데이터 → 차별적 의사결정
총 정리
1. 머신러닝 개념
: 데이터에서 패턴 학습 → 예측/분류 수행
2. 머신러닝, 딥러닝, AI
: AI라는 큰 개념 안에 머신러닝, 그 안에 딥러닝
3. 머신러닝 vs 통계
: 예측 성능 vs 가설 검증
4. 머신러닝 학습 종류
: 지도학습, 비지도학습, 강화학습
5. 모델링 프로세스
: 데이터 수집 → 전처리 → 모델링 → 평가 → 최적화 → 배포
💡실무 팁
: "잘 정리된 데이터가 80%"
: "모델링과 튜닝은 20% 미만"
: 현업 프로젝트에서는 도메인 지식과 머신러닝 지식의 협업이 필수
'머신러닝' 카테고리의 다른 글
| 머신러닝(클러스터링) (2) | 2025.07.08 |
|---|---|
| 머신러닝(앙상블 기법) (0) | 2025.07.07 |
| 머신러닝(분류) (1) | 2025.07.04 |
| 머신러닝(회귀) (2) | 2025.07.03 |
| 머신러닝(데이터 전처리) (2) | 2025.07.02 |



